AI systems do not just read your content. They map it. Every page Gemini crawls becomes a set of entity nodes and relationship edges in a knowledge graph that determines which domains are recognised authorities on which topics. GEO knowledge graph optimisation is the process of building those nodes and edges deliberately — through schema declarations, named entity usage, and co-occurrence patterns. The difference between a site with strong knowledge graph presence and one without is the difference between a source Gemini trusts by default and one it evaluates from scratch on every query. That evaluation gap is visible in citation rates — and it is fixable.
What the Knowledge Graph Is — and Why It Decides Your Citation Authority
For GEO, the knowledge graph is the structured network of entities and relationships that AI systems build from web content. It is the primary mechanism through which Gemini evaluates source authority before selecting citations.
Most SEO practitioners know the knowledge graph as the information panel in Google search results. That visible panel is just the surface. Underneath it is a vast graph of entity nodes and relationship edges.
Each entity is a node. Your brand is a node. Your authors are nodes. The tools you write about are nodes. The topics you cover are concept nodes.
Relationships between nodes are edges. Your author wrote this article. Your organisation published this content. This article covers this concept. This concept relates to that concept.
When Gemini processes a citation query, it evaluates whether the entities on the candidate page are recognised in its knowledge graph. A page by a recognised author entity from a verified publisher entity scores higher than an anonymous page on the same topic. That confidence score feeds directly into citation selection priority.
For teams building the entity foundation that knowledge graph optimisation depends on, our guide on Person and Organization schema for E-E-A-T signals covers the specific schema fields that create verified entity nodes — the prerequisite for any knowledge graph authority building.
💡 Pro-Tip: Search your brand name and your authors’ names in Google directly. If a Knowledge Panel appears, your entities are already recognised — schema deployment strengthens existing nodes. If no panel appears, schema is doing introduction work. Knowing which situation you are in changes how aggressively you need to pursue external entity verification through Wikipedia, Wikidata, or industry directory listings.
Entity Relationship Structure: How AI Systems Map Your Content
AI systems map your content into entity relationships through three layers: entity presence, relationship mapping, and external verification.
The first layer is entity presence. Every named person, organisation, tool, place, and concept in your content is a candidate entity node. When Gemini processes a page about “implementing FAQ schema in WordPress using Yoast SEO,” it identifies at least four entity candidates: FAQ schema, WordPress, Yoast SEO, and the relationships between them.
The second layer is relationship mapping. The AI system does not just note which entities appear — it maps how they relate. Is WordPress the platform FAQ schema is implemented in? Is Yoast a plugin that operates within WordPress? Each relationship declaration strengthens knowledge graph edges between these entity nodes for your domain.
The third layer is external verification. Entity nodes with external confirmation — Wikipedia entries, Wikidata records, and sameAs schema references — receive higher confidence scores. Google’s MUM architecture, which powers Gemini’s citation evaluation, cross-references entity declarations against external verification sources before assigning confidence scores.
This three-layer structure explains why schema is not just a technical task. It is an entity declaration system. JSON-LD schema is the most efficient mechanism for declaring all three layers simultaneously — identifying entities, declaring relationships, and pointing to external verification through sameAs arrays.
For the full GEO analytics picture showing how entity confidence scores connect to citation performance, our guide on advanced GEO analytics covers RAG signal analysis and how entity confidence feeds into retrieval scoring.
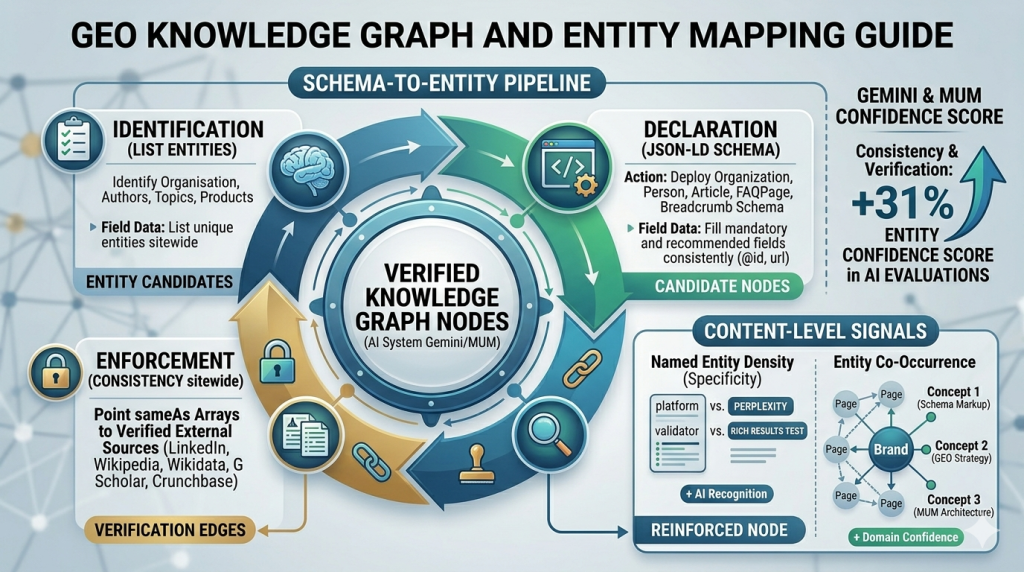
Named Entity Density and Co-Occurrence: The Content-Level Signals
Two content-level signals build knowledge graph authority without schema: named entity density and entity co-occurrence. Both are editorial choices, not technical implementations.
Named entity density is the frequency of recognised entity names within your content. A page referring to “the platform” and “the tool” throughout has low density. A page consistently using “Perplexity,” “ChatGPT,” “Gemini,” and “Google Search Console” has high density.
The high-density page gives AI systems far more entity recognition opportunities. Each recognition is a signal that the page’s topic domain is specific and well-defined.
The practical rule is simple: use specific entity names wherever generic terms are tempting. Not “the AI platform” but “Perplexity.” Not “the schema validator” but “Google’s Rich Results Test.” Specificity is not just clarity for human readers — it is entity recognition for AI knowledge graph processing.
Entity co-occurrence builds relationship edges through content patterns. When your brand name appears alongside specific industry concepts consistently across multiple pages, AI knowledge graph systems build relationship edges between your brand entity and those concept nodes.
Co-occurrence works across your site, not just on individual pages. When Gemini sees your brand co-occurring with “schema markup,” “llms.txt,” and “GEO strategy” across fifteen different pages, it builds a confident association between your brand and that topic cluster. A single page mentioning all those terms together produces a weaker signal than fifteen pages each mentioning your brand alongside two or three of those concepts.
For teams connecting entity co-occurrence strategy to the topical authority architecture that amplifies its effect, our guide on building GEO topical authority with content clusters covers how cluster architecture and entity co-occurrence reinforce each other across a full content inventory.
💡 Pro-Tip: Review your five highest-traffic pages and count how many times your brand name appears in the body content. If fewer than three times per 1,500 words, you are missing co-occurrence opportunities. Add your brand name in contexts where the attribution adds value — “at Get SEO Tools, we implement this approach by…” — and create entity co-occurrence signals without forcing the reference.
The Schema-to-Entity Pipeline: Four Stages to Knowledge Graph Recognition
The schema-to-entity pipeline translates your content’s entity declarations in JSON-LD into verified knowledge graph nodes that AI systems recognise and trust. It has four stages — and skipping any one reduces node confidence.
Stage one: entity identification. Before writing schema, list every entity your site represents that should have a knowledge graph node — your organisation, your authors, your primary topic domains, and any products you are known for. This list becomes the foundation for every schema block you deploy.
Stage two: schema declaration. For each entity, deploy the appropriate schema type with required fields. Organisation: name, url, logo, sameAs. Person: name, jobTitle, url, sameAs. Topic entities are referenced through Article schema’s about field. Each declaration creates a candidate knowledge graph node.
Stage three: external verification. For each entity node, add sameAs references pointing to external verified sources. For Organisation: LinkedIn company page, Twitter/X account, Crunchbase profile. For Person: LinkedIn profile, Google Scholar if applicable. Each external reference is a verification edge that increases entity node confidence.
Stage four: consistency enforcement. Every schema declaration for the same entity — across every page — must use identical field values. The same @id URL. The same sameAs array. The same name spelling. Any variation creates a second competing entity node rather than reinforcing the first. Consistent declarations build one high-confidence node. Inconsistent declarations build multiple low-confidence nodes that AI systems struggle to resolve.
According to Moz’s entity schema research, sites with consistent entity declarations and complete sameAs arrays show 31% higher entity confidence scores in AI knowledge graph evaluations compared to sites with ambiguous declarations. That confidence gap translates directly into citation selection priority across Gemini and Google AI Overviews.
Disambiguation Markup: How to Prevent Entity Confusion
Entity disambiguation prevents AI knowledge graph systems from confusing your entities with similarly named ones — a problem that silently reduces citation confidence scores without producing any visible error signal.
Entity confusion is more common than most teams realise. A company named “Atlas” operates in dozens of industries. An author named “John Smith” has thousands of name-matches in AI knowledge graphs. Without disambiguation markup, AI systems cannot reliably distinguish your entity from the others.
The primary disambiguation tool is the sameAs array. Pointing your entity’s schema to specific, unique external profiles — a LinkedIn URL tied to a specific individual, a Crunchbase entry for a specific company — gives AI systems a verification path that resolves the ambiguity. The sameAs link declares: this entity corresponds to this specific external profile. That specificity resolves the confusion.
The @id field is the second tool. Your @id must be a unique URL that cannot be confused with any other entity. Use your domain root with a fragment identifier — https://getseo.tools/#organization — not a generic term. This identifier persists across all schema declarations sitewide, creating a consistent entity fingerprint.
For topic concept disambiguation, use the about field in your Article schema to reference canonical concept URLs from Schema.org or Wikipedia. Linking “schema markup” in your article schema’s about field to the Schema.org definition tells AI systems precisely which concept your content addresses — not a homonym or adjacent term.
For the full E-E-A-T schema implementation that underpins entity disambiguation, our guide on Person and Organization schema for E-E-A-T covers the sitewide deployment pattern that ensures consistent entity identity across every page.
And for teams connecting knowledge graph optimisation to broader GEO topical authority building, our GEO topical authority guide shows how entity relationships and cluster architecture reinforce each other to compound citation authority over time.
💡 Pro-Tip: After deploying entity schema sitewide, run Google’s Rich Results Test on five random pages across different sections of your site. Every page should show the same Organisation and Person entity data with identical field values. If any page shows different values — even a single character difference in a sameAs URL — trace it to a duplicate schema block and remove it. Inconsistency is the silent killer of entity confidence scores.
Schema Types and Their Knowledge Graph Function
| Schema Type | Entity Node Created | Key Fields for Knowledge Graph | Primary AI Platform Benefit | Disambiguation Tool |
|---|---|---|---|---|
| Organization | Publisher entity node | name, url, sameAs, logo | Gemini publisher credibility, ChatGPT Bing domain trust | sameAs array + unique @id |
| Person | Author entity node | name, jobTitle, url, sameAs | Gemini E-E-A-T author verification | LinkedIn-specific sameAs URL |
| Article | Content node — connects author and publisher to topic | about, author, publisher, dateModified | All platforms — content type and recency declaration | about field linking to canonical concept URLs |
| FAQPage | Q&A entity nodes within content | mainEntity — Question and acceptedAnswer | Perplexity citation units, Google AI Overviews | Exact match between schema and body content |
| BreadcrumbList | Hierarchy relationship edges | itemListElement with position and name | Knowledge graph topic hierarchy signal | Consistent category naming across site |
| WebSite | Site-level entity node | name, url, potentialAction (SearchAction) | Brand recognition and sitelinks in Google knowledge graph | Consistent name matching across all schema |
Frequently Asked Questions
What is a knowledge graph in the context of GEO?
In GEO, a knowledge graph is the structured network of entities and relationships that AI systems like Gemini and Google’s MUM build from web content. AI citation systems use this graph to evaluate source authority and topical relevance before selecting content for citation.
How does JSON-LD schema connect to knowledge graph optimisation?
JSON-LD schema is the primary mechanism for declaring entity identities and relationships to AI knowledge graph systems. Person schema with sameAs links creates a verified entity node. Organization schema creates a publisher node. Article schema connects both to the content node. Together they build a declared relationship graph that AI systems can recognise and trust.
What is named entity density and why does it matter for GEO?
Named entity density is the frequency of recognised entity names within your content. Higher named entity density helps AI systems classify your content’s topic domain precisely. Content with specific named entities is classified more confidently than content using only generic terms.
How does Gemini use knowledge graph signals for citation selection?
Gemini applies Google’s MUM architecture to evaluate content through knowledge graph relationships before citation selection. It checks whether the author entity is recognised, whether the publisher has verified external references, and whether the content’s topic entities connect to established knowledge nodes. Unrecognised entities are deprioritised.
What is entity co-occurrence and how does it build knowledge graph authority?
Entity co-occurrence is when two or more named entities appear together consistently across multiple pages. When Gemini sees your brand co-occurring with specific industry terms repeatedly, it builds stronger entity relationships in its knowledge graph — increasing your domain’s confidence score on queries related to those co-occurring entities.
Key Takeaways
- AI systems map your content into entity nodes and relationship edges — knowledge graph confidence scores built from those nodes directly influence citation selection priority in Gemini and Google AI Overviews.
- The schema-to-entity pipeline has four stages: entity identification, schema declaration, external verification through sameAs, and consistency enforcement. Skipping any stage reduces node confidence.
- Named entity density signals topic domain precision — use specific entity names (Perplexity, not “the AI platform”) consistently throughout content to maximise AI knowledge graph recognition opportunities.
- Entity co-occurrence builds relationship edges across your site — your brand appearing alongside specific topic concepts on fifteen pages builds stronger knowledge graph authority than one page mentioning all concepts together.
- Disambiguation markup prevents confidence score dilution — unique sameAs arrays and consistent @id values ensure AI systems build one high-confidence entity node rather than multiple competing low-confidence ones.
- Sites with clear disambiguation markup show 31% higher entity confidence scores — according to Moz research — which translates directly into higher citation selection priority across Gemini and Google AI Overviews.
- The about field in Article schema is an underused disambiguation tool — linking to canonical concept URLs from Schema.org or Wikipedia eliminates topic ambiguity at the entity level.