
Table of Contents
- Key Takeaways
- PTA in 90 Seconds
- If You Only Do 3 Things This Month
- Definition
- System Context
- Problem Model
- Root Cause Mechanism
- Failure Patterns
- Governance Rules
- Implementation Model
- Artifacts and Templates
- Validation Criteria
- Monitoring and Alerts
- Metrics and Thresholds
- Failure Scenario
- Remediation Protocol
- Decision Framework
- Technical Checklist
- Related Systems
- Conclusion
- Frequently Asked Questions
- Related SEO Articles
Key Takeaways
- PTA is a graph-based architecture, not a content strategy. It governs how equity moves through your URL set — and most sites have no model for this at all.
- The three root failure modes at scale are crawl waste, equity fragmentation, and entity drift. All three are structural. None are fixed by writing better content.
- Deployment readiness depends on system capacity, not URL count. A 300-URL site with canonical governance and crawl log access is more ready than a 2,000-URL site flying blind.
- All thresholds in this document are operational targets and monitoring guardrails — not universal rules. Establish your own baseline first, then track deltas.
- The fastest wins are usually canonical governance at template level and an intent overlap audit. Neither requires new content. Both reduce structural drag immediately.
PTA in 90 Seconds
If you have 90 seconds to understand what Programmatic Topical Authority actually is, here it is:
- Graph model: The domain is a directed weighted graph. Every URL is a node. Every internal link is a weighted edge. Authority accumulates based on graph structure, not content quality alone.
- Intent stratification: Every URL occupies a specific position in an intent model — definitional, procedural, comparative, or transactional. URLs without assigned positions drift into overlap and cannibalize each other.
- Canonical governance: Every URL pattern (pagination, facets, tags, parameters) needs an assigned canonical treatment enforced at the CMS template level — before content is published, not after problems emerge.
- Sequenced publication: Content goes live in defined waves. Pillar pages and commercial targets first, supporting cluster content second. This ensures equity flows into the right nodes from day one.
- Monitoring signals: Three leading indicators tell you if the system is working: canonical crawl share (are the right pages getting crawled?), entity density (is topical signal coherent?), and SERP overlap (are URLs competing instead of complementing?).
- Commercial endpoints: The goal of the whole architecture is to concentrate equity at pages that convert. Everything else — pillars, clusters, support content — is infrastructure for that endpoint.
If You Only Do 3 Things This Month
Not every team can overhaul a content architecture in a sprint. If bandwidth is limited, prioritize these three actions — they address the most common structural failures and produce measurable signals within 30 days:
- Canonical governance at template level: Map every URL pattern type on your site (pagination, tag archives, faceted filters, parameter strings). Assign canonical treatment to each. Implement it at the CMS template level so it applies automatically. This is the single highest-leverage action for crawl efficiency on any site with more than a few hundred URLs.
- Intent overlap matrix: Pull your top 50–100 target URLs. Run SERP overlap scoring across all pairs — use SERP overlap as the measurable proxy for intent overlap in practice. Pairs in the 10–15% range go on the watchlist; 15–25% requires a scheduled review; above 25% needs structural correction now: merge, re-segment, or establish a canonical hierarchy. Left unresolved, competing pairs suppress each other’s rankings — and no amount of link building fixes a structural cannibalization problem.
- Equity injection and leak audit: Use the Authority Tool to export your internal link graph. Identify your highest-authority pages. Check where they send equity. If high-weight pages link to tag archives, noindexed utilities, or external domains rather than commercial endpoints, you have an equity leak. Add direct links from those pages to commercial targets using partial-match anchors. This is free authority you already have — just misrouted.
Definition
Core Architecture
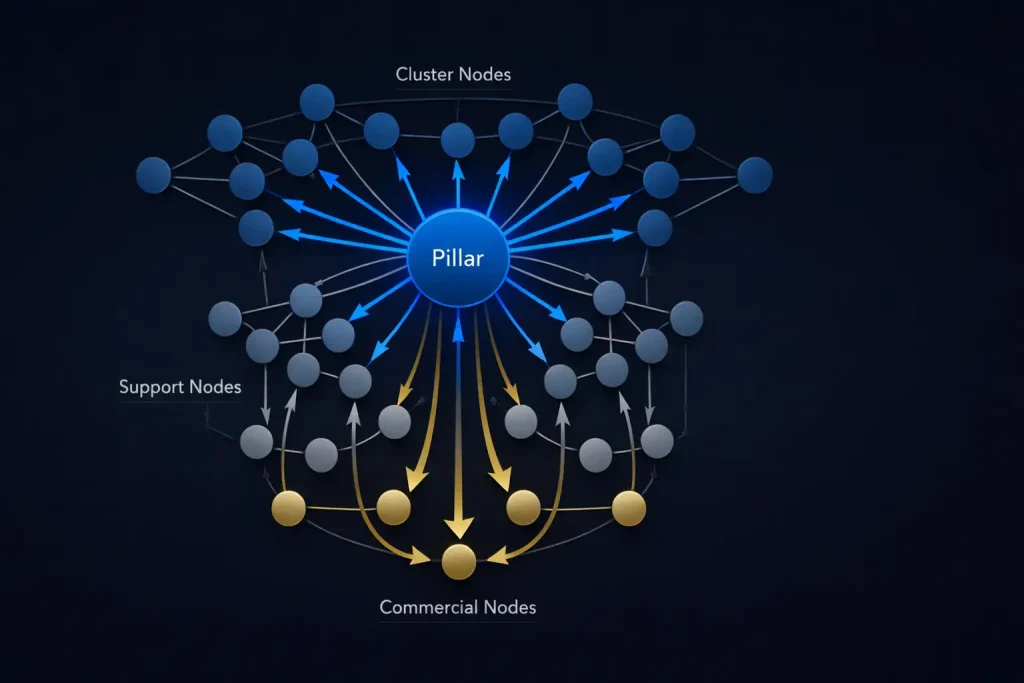
Programmatic Topical Authority (PTA) is a graph-based authority architecture that governs how semantic equity moves across a domain’s URL set at scale. It is not a content strategy, a publishing framework, or a keyword targeting methodology. Rather, it is an engineering model that defines how every URL is positioned within a directed weighted graph, how internal links transfer equity between nodes, and how publication sequencing affects the rate of authority accumulation at commercially significant endpoints.
In PTA, the system treats the domain as a directed weighted graph. Every URL functions as a node. Every internal link operates as a weighted directed edge. Authority accumulation, therefore, follows a pattern tied to graph topology — not content quality in isolation. Topical signal depends on entity co-occurrence density across document sets. As a result, ranking outcomes reflect structural decisions made at architecture design time, not at publication time.
Structural Distinction from Topic Clustering
PTA differs from traditional topic clustering in three structural dimensions. First, the system engineers equity flow before publication rather than managing it editorially afterward. Second, every URL holds a defined node position within the authority graph with an explicit equity direction. Third, publication follows a sequenced matrix based on graph topology — not an editorial schedule or production readiness order.
Deployment threshold: PTA is well-suited for content operations exceeding 500 indexed URLs with production velocity above 20 pieces per month, template-level canonical enforcement capability, crawl log access, and systematic internal link governance. That said, URL count is a weak proxy for readiness — what matters is system capacity. Sites with fewer than 500 URLs can still benefit meaningfully from PTA principles when they face faceted URL proliferation, large documentation sets, or aggressive URL pattern sprawl. Conversely, a site with 5,000 URLs but no crawl log access and no canonical governance is not operationally ready. In lower-velocity contexts, conventional hub-and-spoke clustering with strong canonical hygiene delivers better return on the same investment.
System Context
How Search Systems Evaluate Topical Authority
Modern retrieval and ranking systems evaluate semantic coherence across document sets, not just within individual pages. Consequently, search engines model topical authority through entity association density and document relationship graphs. A domain that publishes extensive content without structural coherence across its URL set will tend to underperform a domain with a smaller, architecturally precise content set — all else being equal.
The PTA system addresses three systemic gaps in conventional SEO architecture at scale.
Gap 1 — Equity modeling absence: Most large-scale content operations do not model how PageRank-equivalent authority flows through their internal link graph. Instead, teams make link decisions editorially, per publication, without reference to the aggregate equity flow pattern across the domain.
Gap 2 — Intent governance absence: Content maps to keyword targets rather than to specific positions within an intent stratification model. Without intent stratification, URL sets accumulate boundary overlap that tends to produce cannibalization at scale.
Gap 3 — Crawl allocation absence: Non-canonical URL variants — faceted navigation combinations, pagination, tag archives, parameter strings — consume Googlebot crawl cycles without contributing canonical authority. On large sites, these non-canonical URL types can consume a substantial share of verified crawl cycles, thereby reducing the crawl frequency available to commercially important canonical URLs.
How PTA Closes These Gaps
PTA addresses all three gaps through pre-publication architecture: graph topology modeling before content production, intent stratification matrix construction before URL creation, and canonical governance enforcement at the CMS template level before deployment. Each gap requires a distinct architectural layer, and all three layers should be in place before content production begins at scale.
Problem Model
Authority Instability at Scale
Large content operations experience compounding authority instability: rankings that fluctuate without corresponding changes in external link profiles, content that earns initial visibility then undergoes ranking decay, and clusters that rank individually but suppress each other at scale due to intent overlap. This instability is structural in origin, not algorithmic. Consequently, algorithmic updates rarely explain these patterns — the cause precedes the symptom by months and can only be found in the architecture itself.
Traditional Clustering Failure at Scale
Manual topic clustering produces authority silos rather than authority networks. Pillar pages accumulate inbound equity but distribute none of it toward commercial conversion targets. Supporting articles link toward the cluster hub but carry no lateral mesh, thus leaving topical adjacency signals absent from the link graph. The structural outcome: cluster hubs rank for head terms, supporting articles rank for nothing, and commercial pages receive no equity reinforcement from the topical content investment.
Traditional clustering tends to degrade above 500 URLs. As URL population grows, equity disperses across unmanaged node sets. Furthermore, no concentration zones are engineered, no intent boundaries are formally defined, and no canonical governance exists at the template level. The result is progressive authority fragmentation rather than compounding authority accumulation.
Isolated System Optimization
Content strategy, link architecture, and technical SEO are typically optimized as independent systems. Each layer may be locally sound while the integrated domain-level architecture remains globally misaligned. PTA, however, imposes unified architectural governance across all three layers simultaneously, treating them as interdependent components of a single graph-based system.
Root Cause Mechanism
URL Proliferation Without Equity Modeling
Each URL added to a domain without an explicit graph position assignment tends to dilute the equity concentration available to high-priority nodes. At scale, unmodeled URL proliferation causes diffuse authority distribution — no single node in a cluster accumulates sufficient weight to function as a reliable authority anchor. As a result, even high-quality content fails to rank predictably when the surrounding graph structure provides no concentrated equity path.
Intent Overlap Without Canonical Governance
Publishing against keyword lists without intent stratification produces URLs that occupy overlapping intent positions. When two URLs in the same domain target queries with significant intent overlap, they compete rather than complement each other. Search systems respond by reducing ranking confidence in both, distributing impressions unpredictably between them. The practical effect is ranking volatility that no amount of content improvement will resolve, because the problem is structural.
Equity Leakage Through Unmodeled Internal Links
Internal link decisions made at the content level — each individually reasonable — can aggregate into a graph that pushes equity toward low-priority destinations: tag archives, utility pages, noindexed content, external domains. High-authority source pages distribute equity through paths that do not terminate at commercial endpoints. Consequently, the commercial pages that most need equity concentration receive little from the internal graph.
Node Weight and Outbound Link Dilution
Every URL carries a node weight — a proxy for accumulated authority — based on the volume, quality, and source authority of its inbound edges, adjusted by its total outbound link count. As a general pattern, pages with many outbound links distribute their available equity more thinly across all destinations than pages with few outbound links. This is a rough proxy model, not a precise calculation — but the directional implication is consistent: pillar pages and commercial targets benefit from high inbound-to-outbound ratios. Pages functioning as redistribution nodes pass equity through rather than accumulating it.
Directed Edge Logic
Equity transfer is directional. A link from node A to node B transfers a portion of A’s distributable weight to B, and that portion varies roughly with A’s total outbound link count. Consequently, links from high-authority pillar pages tend to deliver more concentrated equity to a commercial endpoint than many links from thin supporting pages. Concentrated equity flow from fewer high-weight sources tends to outperform diffuse flow from many low-weight sources — a counter-intuitive result for teams accustomed to maximizing link volume.
Failure Patterns
Crawl-Share Misallocation
Googlebot distributes crawl cycles across all discoverable URLs. On sites without canonical governance, non-canonical URL types — faceted navigation variants, parameter combinations, pagination, tag archives — consume an outsized share of available crawl budget. When non-canonical URLs consume more than roughly half of verified Googlebot requests, canonical content URLs receive suppressed crawl frequency — reducing indexing freshness and slowing authority signal propagation. The specific threshold varies by site architecture; track your own baseline trend rather than targeting a single number.
Equity Fragmentation
Internal links scatter PageRank-equivalent weight across thin supporting content rather than concentrating it at pillar nodes and commercial endpoints. This problem occurs when teams make link decisions editorially without reference to the equity flow model. The aggregate effect is a flat authority distribution across the URL set — no node accumulates sufficient weight to function as a reliable ranking anchor. Even technically sound content will underperform in this structural condition.
Intent Cannibalization
Multiple URLs compete for identical or near-identical query intent without canonical resolution. Standard per-keyword ranking monitoring does not detect cannibalization. Instead, it manifests as impression volatility — rankings shifting between two domain URLs for the same query — and only surfaces through SERP overlap scoring across URL pairs. By the time ranking instability becomes visible, the structural conflict has typically been active for months.
Depth Misconfiguration
Supporting cluster content at click depth four or five receives suppressed crawl frequency regardless of content quality. Crawl frequency tends to correlate with click depth: URLs requiring more navigational steps from the homepage generally get crawled less frequently. Supporting content at depth four or higher, therefore, cannot accumulate authority at the rate required to reinforce pillar nodes effectively.
Anchor Text Entropy
When the same destination URL receives a large number of distinct anchor text variants across internal links, the topical signal for that destination becomes diffuse. Search systems cannot confidently associate the destination URL with a specific topical territory when anchor signals span unrelated phrases. As a result, topical signal concentration requires controlled anchor variation — three to five approved variants per destination — rather than unconstrained editorial anchor choice.
Cross-Cluster Contamination
Supporting articles that link to adjacent cluster hubs using anchors associating the source page with the destination cluster’s primary entity create entity signal ambiguity at the source. A URL associated with two distinct cluster entities provides weak topical signal for either. At scale, cross-cluster contamination produces a domain-level topical signal that is diffuse rather than precise, making it harder for search systems to attribute clear topical territory to the domain.
Entity Drift
Content updates that introduce secondary entity associations competing with the cluster’s primary entity progressively dilute primary entity co-occurrence density. A cluster that launched with high primary entity coherence across its URL set may degrade significantly over 18 months of incremental updates — each individually minor, but collectively producing a topically ambiguous cluster. As a result, the cluster receives weaker authority attribution from search systems, despite no single update appearing problematic in isolation.
Graph Cohesion Failure
When entity signals become inconsistent across URL sets — conflicting primary entity declarations, schema markup misaligned with content structure, inconsistent Organization schema name properties — search systems cannot confidently assign topical territory to the domain. Consequently, knowledge graph alignment weakens, reducing the cluster’s ability to trigger entity-associated rich results and knowledge panel features.
Governance Rules
The rules below are operational targets and monitoring guardrails, not universal laws. Establish your own site baseline first — then track trends and deltas relative to that baseline. A site improving from 35% canonical crawl share toward 55% is making meaningful progress, even if it hasn’t reached a published target figure.
Canonical Crawl Share Rule
Operational target: canonical content URLs should account for roughly 60–70% of verified Googlebot requests. This target is site-type dependent — heavy ecommerce with faceted navigation will have a different structural baseline than a lean editorial site. Track the trend first; a sustained decline below your established baseline is the real intervention trigger. A reading consistently below 50% on most site types warrants immediate structural review. Low-value non-canonical patterns — parameter variants, thin filters, tracking strings — should be kept to roughly 10–15% on most sites; the remainder will vary across necessary supporting URLs and templates such as pagination, sitemaps, and canonical alternates.
Node Weight Ratio Rule
Pillar-tier URLs benefit from high inbound-to-outbound link ratios — a rough target of 4:1 or better. Ratios falling below 2:1 are a signal to inject links from supporting cluster content and remove outbound links to low-priority destinations. Commercial endpoint URLs should function as terminal receivers: high inbound equity, minimal outbound dilution.
Entity Density Rule
Entity “presence” in PTA refers to topical focus and entity classification — not raw keyword mentions. A URL “has” the primary entity present when that entity is the dominant topical classification of the document, as determined by NLP extraction and entity recognition. This is about coherent topical framing in natural writing, not stuffing entity names into paragraphs. Pick one extraction and classification method, run it across the whole cluster, and track change against your baseline over time.
Operational target: the primary entity should function as the dominant topical classification in roughly 90% or more of URLs within a cluster. The top three secondary entities should co-occur meaningfully in around 60% or more of cluster URLs. A primary entity presence rate below 80% (by this classification measure, not mention count) triggers a content realignment review. Furthermore, publishing new URLs during a period of low entity density only expands the problem surface without resolving existing dilution.
Intent Overlap Rule
Use SERP overlap as the measurable proxy for intent overlap in practice. Any two URLs within the same domain sharing significant SERP overlap require either consolidation or an explicit canonical hierarchy assignment. The tiered monitoring system: 10–15% is a watchlist signal — schedule a review; 15–25% requires structural review; above 25% requires corrective action. The exact intervention point depends on the query set and vertical, but the direction of travel matters more than any single snapshot reading.
Depth Governance Rule
Supporting cluster content should be reachable at click depth three or fewer from the homepage. Content at depth four or higher is structurally suppressed and therefore requires inbound link injection to reduce its effective depth. This applies regardless of content quality — depth suppression is a structural constraint, not a content quality judgment.
Schema Consistency Rule
Organization schema name properties must be identical across all domain URLs. Similarly, Article schema should apply exclusively to editorial content URLs. BreadcrumbList schema must accurately reflect cluster hierarchy. In addition, author entity declarations in Article schema should be consistent with verified external author profiles where applicable.
Anchor Text Governance Rule
Each destination URL in the internal link anchor map should have three to five approved anchor text variants: exact-match, partial-match, and contextual-partial forms. Template-level links use the primary partial-match variant consistently. Contextual editorial links rotate within the approved variant set. Generic anchors — “click here,” “learn more,” “this article” — are counterproductive in contextual link positions.
Publication Sequencing Rule
Content production follows a defined wave matrix. Wave one covers entity pages, pillar pages, and commercial target pages. Subsequently, waves two and three cover supporting cluster articles in descending semantic adjacency score order. Wave four, finally, covers FAQ content, long-tail targets, and cross-cluster bridge articles. Cross-cluster content does not publish until both connected cluster cores are fully established.
Implementation Model
Phase 1 — Architecture Design
Before content production begins, the team must design the full authority graph. This requires defining the entity layer (domain entity, topical territory, geographic scope), the pillar layer (primary authority nodes per head-term keyword family), the cluster layer (supporting articles per pillar), the support layer (FAQ, long-tail, technical content), and the commercial endpoint layer (product, service, and conversion pages).
Each URL in the planned architecture receives a node position assignment, an intent stratification position, a semantic adjacency score relative to its cluster core, and a production wave assignment. The internal link anchor map, moreover, is defined at architecture design time — not post-publication.
Phase 2 — Canonical Governance Implementation
The team constructs a URL pattern governance map before content production begins. Every URL type receives an assigned canonical treatment: full index with equity accumulation, noindex with canonical to parent, disallow at robots.txt, or canonical to clean URL. The CMS template layer then enforces these assignments automatically across all future URLs of each type — eliminating per-page manual review. Specifically: blog pagination receives noindex plus canonical to root archive; tag pages receive noindex; faceted filter combinations receive disallow or canonical to clean URL; and product variants receive canonical to primary variant.
Phase 3 — Equity Flow Modeling
Export the full internal link graph using Screaming Frog, Sitebulb, or a comparable crawl tool. Calculate node weight scores using inbound link counts weighted by source page authority. Identify concentration zones where inbound links converge on a small number of high-priority destinations. Then identify weak graph zones — URL sets with diffuse inbound patterns and no clear high-weight node — as remediation targets. The Authority Tool can help map this distribution before and after architectural changes.
Phase 4 — Intent Stratification Matrix Construction
Every planned URL receives an assignment to a specific intent stratum — not a general category, but a specific position within the intent model. Definitional content sits at the informational apex. Procedural content occupies the next stratum. Comparative content bridges informational and commercial layers. Transactional content, therefore, occupies the commercial terminus. Each intent position has defined content properties: length range, structural format, internal link directionality, and canonical relationship rules.
Any two planned URLs sharing significant intent overlap are flagged for consolidation or canonical hierarchy assignment before production begins. This pre-publication check prevents structural cannibalization from reaching the live index.
Phase 5 — Entity Layer Mapping
The team extracts named entity sets from existing top-ranking content for each target query cluster. Subsequently, comparing entity overlap between each planned URL and its cluster core yields semantic adjacency scores. URLs with low entity overlap relative to the cluster’s primary entity require content restructuring before publication. Entity co-occurrence targets are then defined: primary entity functioning as the dominant topical classification in roughly 90% of cluster URLs, top three secondary entities co-occurring meaningfully in around 60% of cluster URLs.
Phase 6 — Sequenced Publication
Production follows the wave matrix. The first wave covers entity pages, pillar pages, and commercial targets. Supporting articles with the highest adjacency scores go out in wave two, followed by remaining cluster content in descending adjacency order during wave three. Finally, wave four handles support and cross-cluster content — but only after both connected cluster cores are fully established. After each wave, the team verifies that internal link equity chains are intact before the next wave begins.
Phase 7 — Ongoing Governance and Decay Monitoring
Every URL receives a decay score based on crawl frequency trend, impression share trend, and entity density alignment score. URLs with deteriorating scores on two or more dimensions enter the update queue. Content updates target entity density realignment first — ensuring the page’s topical classification profile matches the current top-ranking content set — before structural or length changes. Furthermore, crawl logs are reviewed monthly for canonical crawl share compliance, and the cannibalization tracking matrix is updated monthly with SERP overlap scoring across all domain URL pairs.
Artifacts and Templates
The four templates below are working examples — minimal but functional. Copy and expand them to fit your actual URL architecture and cluster size. They’re designed to be maintained in a shared spreadsheet or project wiki, not buried in a doc no one opens.
Template 1: Intent Stratification Matrix
| URL / Slug | Intent Stratum | Primary Query Target | Content Format | Link Direction | Canonical Rule |
|---|---|---|---|---|---|
| /what-is-topical-authority/ | Definitional (Informational Apex) | what is topical authority | Long-form explainer | Outbound → Pillar | Self-canonical |
| /topical-authority-guide/ | Procedural | how to build topical authority | Step-by-step guide | Outbound → Pillar + Commercial | Self-canonical |
| /topical-authority-vs-domain-authority/ | Comparative | topical authority vs domain authority | Comparison article | Outbound → Pillar | Self-canonical |
| /seo-tools/authority/ | Transactional (Commercial Terminus) | topical authority tool | Tool landing page | Terminal receiver | Self-canonical |
| /blog/tag/topical-authority/ | N/A — non-canonical | — | Tag archive | None | Noindex |
| /topical-authority/?sort=newest | N/A — parameter variant | — | Parameterized | None | Canonical → /topical-authority/ |
Template 2: URL Pattern Governance Map
| URL Pattern Type | Example | Canonical Treatment | Index Status | Robots.txt Rule | Notes |
|---|---|---|---|---|---|
| Blog pagination | /blog/page/2/ | Canonical → /blog/ | Noindex | Allow | Exclude from sitemap |
| Tag archive | /blog/tag/seo/ | Self or noindex | Noindex | Allow | No internal link equity |
| Faceted filter (sort) | /products/?sort=price | Canonical → /products/ | Noindex | Disallow (low value) | High crawl waste risk |
| Faceted filter (color) | /products/shoes/?color=red | Evaluate for standalone | Index if high traffic intent | Allow if indexed | Promote top variants to canonical standalone |
| Product variant | /product/widget-blue/ | Canonical → /product/widget/ | Noindex | Allow | Unless distinct commercial intent |
| UTM / tracking params | /page/?utm_source=email | Canonical → /page/ | Noindex | Disallow | Strip in GSC parameter settings |
Template 3: Anchor Governance Map
| Destination URL | Primary Entity / Topic | Exact-Match Anchor | Partial-Match Anchor | Contextual-Partial Anchor | Prohibited Anchors |
|---|---|---|---|---|---|
| /seo-tools/authority/ | Topical authority analysis | topical authority tool | authority analysis tool | analyze your authority graph | click here, learn more, this tool |
| /what-is-topical-authority/ | Topical authority definition | what is topical authority | topical authority explained | how topical authority works | here, read more, this article |
| /internal-linking-graph/ | Internal link equity flow | internal linking graph | link equity architecture | how internal links flow equity | internal links, read this |
| /topical-authority-guide/ | Building topical authority | topical authority guide | building topical authority | how to develop authority clusters | guide, full guide, click |
| /canonical-governance/ | Canonical URL governance | canonical governance | canonical URL management | managing canonical directives | canonical tags, this page |
Template 4: Wave Publication Matrix
| Wave | URL / Page Type | Intent Stratum | Adjacency Score | Target Pub Date | Equity Chain Check |
|---|---|---|---|---|---|
| Wave 1 | /seo-tools/authority/ (commercial target) | Transactional | N/A — anchor node | Week 1 | — |
| Wave 1 | /programmatic-topical-authority/ (pillar) | Definitional / Procedural | N/A — pillar node | Week 1 | Links to commercial target? ✓ |
| Wave 2 | /internal-linking-graph-architecture/ (cluster) | Procedural | 0.82 | Week 3 | Links to pillar? ✓ |
| Wave 2 | /intent-stratification-matrix/ (cluster) | Procedural | 0.78 | Week 3 | Links to pillar? ✓ |
| Wave 3 | /canonical-governance-guide/ (cluster) | Procedural | 0.65 | Week 5 | Links to pillar? ✓ |
| Wave 4 | /topical-authority-faq/ (support) | Informational support | 0.44 | Week 7 | Both cluster cores established? ✓ |
Validation Criteria
Architecture Layer Validation
A well-modeled authority graph shows increasing PageRank proxy values at pillar nodes, decreasing values at support nodes, and consistent equity concentration at commercial targets. A functioning cluster architecture also shows supporting content at depth three maximum, hub pages linking to commercial targets with partial-match anchors, and zero generic anchor usage in contextual link positions.
Crawl Governance Validation
Establish a crawl share baseline from your first month of server log segmentation. Use that as your reference point. As an operational target, canonical content URLs should trend toward 60–70% of verified Googlebot requests on most site types, with low-value non-canonical patterns kept to roughly 10–15%. Monthly crawl log analysis confirms whether these distributions are trending in the right direction — improvement matters more than hitting a specific number immediately.
Entity Layer Validation
Knowledge graph alignment success produces branded and entity-associated queries that trigger knowledge panels and entity-specific rich results. These SERP features are tracked monthly. Progressive improvement in entity feature triggers over a 90-day window confirms cohesion improvement and validates that schema reinforcement and entity density targets have been reached.
Sequencing Validation
After wave one publication, pillar pages must receive internal links from wave two content before wave three begins. Any gap in the equity chain — supporting content published without linking to its pillar — breaks the sequencing model and requires correction. Sequenced publication typically produces measurable crawl frequency advantages within 14 to 21 days of pillar publication, which is verifiable in server logs.
Commercial Layer Validation
Commercial layer recovery shows three confirming signals across distinct measurement windows. In the 30-day window, crawl frequency increases for commercial target URLs in server logs, confirming that equity flow delivers crawl priority correctly. In the 45-to-60-day window, GSC impression share growth for commercial target keyphrases confirms SERP feature acquisition. In the 90-day window, organic conversion attribution from cluster-origin traffic to commercial target conversions confirms that the full authority pipeline is operational.
Monitoring and Alerts
Technical Layer — Monthly
Server log segmentation by Googlebot user-agent string measures crawl share by URL type. The team reviews response code distribution for 4xx and 5xx patterns on canonical URLs. Rendering latency measurements by template type identify JavaScript-rendered content with delayed indexing. Monitoring trigger: a sustained decline in canonical crawl share below your established baseline warrants investigation; a drop below 50% on most site types warrants immediate structural review.
Authority Layer — Monthly
The team reviews internal link equity distribution by exporting the full link graph to recalculate inbound-to-outbound ratios by URL tier. An entropy check on anchor text distribution per destination follows each export. Monitoring trigger: pillar-tier ratio trending below 3:1 signals a link injection review; a ratio below 2:1 warrants mandatory remediation.
Content Layer — Quarterly
The team calculates entity density alignment scores by comparing named entity classification profiles of cluster URLs against current top-ranking competitor content. In addition, the review covers intent stratification accuracy using SERP overlap scoring across all URL pairs: 10–15% enters the watchlist, 15–25% triggers a scheduled review, and above 25% triggers the cannibalization decision framework. Semantic adjacency scores are then recalculated per cluster after significant publishing waves. Monitoring trigger: primary entity presence below 80% triggers the update protocol.
Commercial Layer — Weekly
GSC tracks impression share by intent tier with 4-week trend monitoring. The team tracks average ranking position by intent tier on a weekly basis. CTR by schema enhancement type is monitored for decline signals. Monitoring trigger: a 5% impression share decline over four weeks triggers a cluster audit; a 10% decline triggers a full structural review.
Decay Monitoring — Continuous
The system combines crawl frequency trends from server logs, impression share trends from GSC, and entity density alignment scores from quarterly audits to update URL-level decay scores on a rolling basis. URLs deteriorating on two or more dimensions simultaneously enter the update queue. To close a decay flag, the team must confirm a crawl frequency increase within approximately 14 days post-update and impression share recovery within roughly 45 days — timelines that vary by site and vertical.
Metrics and Thresholds
All figures below are operational targets and monitoring guardrails — not universal thresholds. Establish your site’s own baseline values first, then use these as directional benchmarks and trigger points for investigation. Delta-based monitoring (tracking change over time from your baseline) is more reliable than comparing against published figures for a different site type.
| Metric | Operational Target | Warning Signal | Investigation Trigger | Risk Level | Corrective Action |
|---|---|---|---|---|---|
| Canonical content crawl share | ~60–70% (site-type dependent; track baseline trend) | Sustained decline below baseline or below ~55% | Below 50% or significant baseline drop | Critical | Enforce canonical directives at template level; disallow non-canonical URL patterns; audit faceted navigation |
| Non-canonical URL crawl share (low-value patterns) | Roughly 10–15% guardrail on most sites; track baseline trend | Trending upward from established baseline | Sustained upward trend or sharp spike above baseline | High | Expand disallow rules; audit canonical directive consistency; identify new parameterized URL pattern types |
| Pillar inbound-to-outbound ratio | ~4:1 or better | Trending below 3:1 | Below 2:1 | High | Remove outbound links to low-priority destinations; inject links from supporting cluster content |
| Primary entity presence rate per cluster | ~90%+ (by topical classification, not mention count) | Below 85% | Below 80% | High | Content realignment to strengthen topical classification coherence; schema review; halt new URL publication until resolved |
| Secondary entity co-occurrence rate | ~60%+ for top 3 secondary entities | Below 50% | Below 40% | Medium | Content expansion targeting secondary entity mentions in natural writing; update internal link anchor text |
| SERP overlap between URL pairs | Below 10% (monitoring guardrail; vertical-dependent) | 10–15% — watchlist; schedule review | 15–25% — review required; 25%+ — action required | High | Apply merge/canonical/re-segment decision tree; document outcome in governance log |
| Supporting content click depth | Depth 3 maximum from homepage | Depth 4 | Depth 5+ | Medium | Add internal links from shallower pages; surface cluster articles in navigation or related content modules |
| Crawl frequency for priority URLs | Weekly or higher | Bi-weekly | Monthly or less frequent | High | Depth audit; inbound link injection from high-authority pages; content freshness update |
| Organic impression share by cluster | Stable or increasing vs. baseline | 5% decline over 4 weeks | 10% decline over 4 weeks | High | Full cluster audit; entity density review; cannibalization check; schema validation |
| Average ranking position by intent tier | Stable or improving vs. baseline | 2-place decline | Sustained 2+ place decline for 3+ weeks | High | Structural review; intent re-segmentation audit; competitor entity profile comparison |
| CTR by enhancement type | Stable or improving vs. baseline | 10% CTR decline | Sustained 10% CTR decline | Medium | Schema validation; rich result eligibility audit; content quality review for featured snippet targets |
| Anchor text variants per destination | 3–5 approved variants | 6–10 variants | 10+ variants (entropy risk) | Medium | Standardize anchor text across template-level links; update contextual links to approved variant set |
Failure Scenario
Ecommerce Site: Compounded Crawl Waste and Entity Drift
Site Profile
An ecommerce operation with approximately 50,000 indexable URLs across product pages, category pages, editorial content, and faceted navigation variants. The site’s filtering system generates parameterized URL combinations for sort order, color, size, and availability attributes. At the time of diagnosis, none of these parameter variants are disallowed or canonicalized.
Observable SEO Signals
Category page rankings decline gradually over eight months. No major algorithm updates correlate with the timing. External link acquisition continues at historical pace. The internal team attributes the decline to content quality and initiates a content refresh program targeting the editorial cluster — however, this is an incorrect diagnosis that addresses the wrong layer entirely.
Indexing and Ranking Impact
Server log segmentation by Googlebot user-agent reveals that only 38% of verified Googlebot crawl cycles reach canonical category and product pages. The remaining 62% distributes across parameterized URL variants. As a result, the canonical category pages that most need frequent recrawl receive the least crawl investment.
Simultaneously, an entity co-occurrence audit of the top-performing editorial cluster reveals degraded entity density. The cluster was originally built around a specific product category as its primary entity. Over 18 months of incremental content updates, however, secondary entities from adjacent lifestyle subject matter have grown in co-occurrence frequency. Primary entity presence has consequently declined well below the 80% intervention threshold — with no single update appearing problematic in isolation.
Root Cause
Two compounding structural failures operate simultaneously. First, the absence of canonical governance at the template level allows faceted navigation to generate hundreds of non-canonical URL variants that compete with canonical URLs for crawl allocation. Second, the absence of entity density monitoring allows incremental content updates to progressively dilute the cluster’s primary entity signal over 18 months. Neither failure is detectable through standard ranking monitoring alone — both require dedicated structural measurement infrastructure.
Remediation Steps
Phase 1 — Crawl waste remediation: The team enforces canonical directives at template level for all filter parameter combinations. The five highest-traffic filter variants are promoted to canonical standalone pages with distinct intent targeting. Robots.txt disallow rules expand to cover low-value parameter combinations. In addition, weekly crawl log monitoring is established as an ongoing operational requirement.
Phase 2 — Entity drift remediation: The editorial cluster undergoes targeted content updates — not full rewrites — focused on reintroducing primary entity topical coherence in the URLs showing the lowest entity presence scores. The team audits schema markup for sameAs property consistency across all cluster pages. No new URLs are published during the remediation period, because new publication would expand entity surface area without resolving existing dilution.
Validation Signals Confirming Recovery
Within 21 days of canonical enforcement, server logs show canonical content crawl share increasing from 38% toward 61%. Within 45 days, GSC data shows impression recovery for category-level target queries. At 60 days, entity density remediation returns primary entity presence to 88% across the cluster. At 90 days, the editorial cluster recovers ranking positions for the top-five target queries. The content refresh program that was originally planned would have added new URLs with new entity associations — thereby compounding the drift failure rather than resolving it.
Remediation Protocol
Legacy Site Remediation Sequence
Retroactive deployment of PTA on a site with existing legacy cluster architecture follows a defined remediation sequence that differs substantially from greenfield deployment.
Steps 1–2: Baseline Audit and Canonical Governance
Step 1: Export the full internal link graph. Calculate inbound-to-outbound ratios per URL and establish baseline node weight scores for all URLs. Then identify equity leakage points in the top 20% of authority-holding pages.
Step 2: Implement canonical governance at the CMS template level. Every URL pattern type receives a canonical treatment assignment. Enforce all assignments before any content production or revision begins.
Steps 3–5: Cannibalization, Entity Density, and New Production
Step 3: Run SERP overlap scoring across the existing URL set. Apply the cannibalization decision framework to all pairs in the review-required range (15–25%) and take immediate corrective action on pairs above 25%. Document all merge and canonical decisions in the governance log.
Step 4: Conduct an entity co-occurrence audit across all cluster URL sets. Identify clusters below the 80% primary entity presence threshold. Execute content updates to restore entity density before any new publication proceeds.
Step 5: After structural remediation is complete — canonical governance in place, major cannibalization resolved, entity density restored — begin new content production following the sequencing matrix.
Equity Leakage Remediation
Identify high-authority pages that distribute equity to noindexed pages, external domains, or utility pages with no onward link to commercial targets. These are leak points. Add commercial target links from these pages using partial-match anchors. Remove or redirect links toward canonical destinations. Furthermore, noindex tag archives that receive equity from site-wide footer or navigation links, and redirect that equity flow toward pillar and commercial pages through template-level link changes.
Entity Drift Remediation
Entity drift correction requires targeted content updates to affected URLs rather than new URL publication. Start by identifying the URLs with the lowest primary entity presence scores in the cluster — typically 14 to 20 pages. Content updates in those URLs should increase primary entity topical coherence through richer, more focused entity framing in natural writing. Schema markup then needs realignment for consistency across name, sameAs, and author properties. New URL publication must stop until primary entity presence returns to threshold, since adding URLs during remediation only widens the dilution surface. Finally, validate recovery through entity extraction re-audit at 60 days post-remediation.
Cannibalization Remediation
When SERP overlap between two domain URLs exceeds 25%, apply the decision framework immediately. If both URLs occupy the same intent stratum, consolidate through 301 redirect — the lower-performing URL merges into the stronger. If URLs occupy adjacent but distinct intent strata, instead apply structural re-segmentation: rewrite one URL to anchor firmly in its assigned intent position through entity density adjustment and structural format changes. Apply canonical tags only when one URL functions as the authoritative target and the other provides contextual support with no independent ranking ambition. Canonical assignment does not resolve genuine intent competition — it masks it temporarily while the structural conflict persists.
Decision Framework
Cannibalization Decision Tree
Input: SERP overlap between URL pair reaches the review-required range (15–25%) or above. Pairs above 25% require immediate action; pairs in the 15–25% range require a scheduled structural review.
Step 1: Compare intent positions of both URLs in the stratification matrix.
Branch A — Same intent position: Consolidate. Merge the lower-performing URL into the stronger through 301 redirect. Update all internal links pointing to the redirected URL. Document the outcome in the governance log.
Branch B — Adjacent intent positions: Evaluate whether content structure makes the intent distinction legible to search systems. If the distinction is legible, re-segment: rewrite one URL to anchor firmly in its assigned intent stratum through entity density adjustment and structural format changes. If the distinction is not legible, apply canonical: implement a canonical tag on the secondary URL pointing to the primary, then evaluate for full consolidation at the next review cycle.
Branch C — Distinct intent positions with unexplained overlap: Audit entity profiles of both URLs for cross-contamination. Identify and remove entity associations that create topical ambiguity. Validate results at 45 days post-remediation.
Deployment Readiness Decision
Evaluate deployment readiness against five criteria: URL scale and pattern complexity (500+ indexed URLs is a rough signal, but faceted URL proliferation and pattern sprawl can justify PTA well below this), content velocity (20+ pieces per month is a working threshold), technical implementation capacity (template-level canonical rule enforcement), measurement infrastructure access (server log access and GSC API), and governance enforcement capability (internal link anchor governance across all content contributors). URL count is a weak proxy — readiness beats size. Failure on two or more criteria indicates premature deployment. In that case, proceed with conventional hub-and-spoke clustering until readiness thresholds are met.
Content Update vs. New Publication Decision
When authority signals for an existing cluster are degrading, apply the following logic. If the primary entity presence is below 80%, execute content updates to existing URLs — do not publish new URLs. If the semantic adjacency score of the cluster’s weakest URLs is below 40%, restructure existing content before adding new URLs. New URL publication is appropriate only when existing cluster architecture meets all governance thresholds and the new URL fills a defined intent position gap with low projected SERP overlap against existing URLs.
Technical Checklist
Pre-Deployment
- Authority graph designed with all URL node positions, intent positions, and wave assignments defined
- URL pattern governance map completed with canonical treatment assigned to every URL type
- Canonical governance implemented at CMS template level before any content production
- Internal link anchor map defined with 3–5 approved anchor text variants per destination URL
- Intent stratification matrix constructed with all planned URLs assigned to specific intent strata
- SERP overlap simulation run for all planned URL pairs — pairs at 10–15% flagged for watchlist; pairs at 15%+ scheduled for review before publication
- Semantic adjacency scores calculated for all planned cluster URLs
- Entity co-occurrence targets defined for primary and top three secondary entities per cluster
- Wave publication matrix finalized and approved
- Crawl log monitoring infrastructure established
Post-Wave-One
- Pillar and commercial target URLs confirmed indexed in GSC
- Schema markup validated for all wave-one URLs — Article, Organization, BreadcrumbList
- Internal links from wave-one URLs to commercial targets confirmed with partial-match anchors
- Crawl log baseline established for wave-one URL set
- Wave-two publication does not begin until wave-one equity chain is confirmed intact
Ongoing Operations
- Monthly: crawl log segmentation — canonical crawl share confirmed above baseline and above 50% floor
- Monthly: internal link graph export — pillar-tier ratios confirmed above 2:1
- Monthly: SERP overlap scoring across all domain URL pairs — cannibalization matrix updated
- Quarterly: entity co-occurrence audit across all cluster URL sets
- Quarterly: semantic adjacency score recalculation for active clusters
- Weekly: GSC impression share monitoring by cluster and intent tier
- Weekly: ranking position monitoring by intent tier with 3-week trend alerting
- Per publication: pre-publication overlap simulation against existing URL set
- Per update: decay score recalculation for updated URL within 14 days of publication
Related Systems
Index Governance
Index governance is the architectural decision layer that determines which URLs exist in the index and in what canonical relationship to each other. It operates upstream of crawl budget optimization. When canonical governance is implemented at template level, crawl budget waste becomes structurally unlikely rather than requiring periodic remediation. For this reason, index governance and PTA share the same template-level enforcement model and should be designed concurrently.
Internal Equity Flow Control
Internal equity flow control governs the directed movement of PageRank-equivalent weight through the internal link graph. It is the operational layer of PTA’s directed edge logic. Specifically, equity flow audits — identifying leak points where high-authority pages distribute to low-priority destinations — form a component of the monthly authority layer measurement cycle.
Content Decay Control
Content decay control is the ongoing maintenance layer of PTA. Decay detection operates on crawl frequency trend, impression share trend, and entity density alignment score simultaneously. Rather than functioning as a standalone system, it serves as the signal layer that determines which URLs enter the content update queue and in what priority order.
Schema and Structured Data Governance
Schema markup provides the explicit entity declaration layer that complements implicit co-occurrence signals. Article schema, Organization schema, BreadcrumbList schema, and author entity declarations all contribute to knowledge graph alignment. Schema governance is a component of entity reinforcement — it must be maintained consistently across all cluster URLs for graph cohesion to hold.
Conventional Topic Clustering
Traditional topic clustering is the predecessor architecture that PTA replaces at scale. It remains appropriate for lower-velocity sites and is a reasonable starting point before PTA readiness is established. Understanding its failure modes — authority silos, depth misconfiguration, anchor text entropy, cross-cluster contamination — is prerequisite knowledge for PTA architecture design, particularly during legacy site remediation.
Conclusion
Structural Value of the Architecture
Programmatic Topical Authority is a governance architecture, not a publishing methodology. Its operational value derives from decisions made before content production begins: graph topology definition, intent stratification, entity target modeling, canonical governance enforcement, and publication wave sequencing. These structural decisions determine whether authority compounds or fragments as URL population grows.
Why Structural Failures Scale Predictably
At the scale for which PTA is designed — content operations exceeding 500 URLs with sustained production velocity — the failure modes of unstructured content operations follow a predictable, recognizable pattern. Crawl waste, equity fragmentation, intent cannibalization, and entity drift tend to emerge without architectural governance. PTA therefore provides the governance framework to address these failures at the structural level rather than remediating them reactively after they damage ranking performance.
The Role of Leading Indicators
The measurement framework distinguishes PTA from conventional SEO approaches through its use of leading indicators — canonical crawl share, node weight ratios, entity density scores, SERP overlap percentages — that signal structural problems before they appear in traffic data. This approach enables intervention timelines measured in weeks rather than the months required for reactive remediation. As a result, teams that operate this measurement framework consistently can intercept the compounding decay cycles that make large-site SEO difficult to manage.
Deployment Guidance
System readiness, not site size, determines deployment suitability. A 300-URL site with full technical implementation capacity, consistent content velocity, and crawl log access is more operationally ready for PTA than a 2,000-URL site without canonical governance and without measurement infrastructure. Start with a baseline equity distribution audit to establish the current state of the domain graph before designing any architectural changes. The deployment decision should rest on the five readiness criteria defined in the Decision Framework section, not on URL count alone.
Frequently Asked Questions
What distinguishes Programmatic Topical Authority from traditional topic clustering at a system level?
Traditional topic clustering is an editorial content organization model. Articles are grouped by subject proximity and published based on production readiness. Programmatic Topical Authority, however, is a graph-based authority architecture where every URL occupies a defined node position, every internal link is an engineered equity transfer, and publication follows a sequenced matrix based on graph topology rather than editorial schedule. Traditional clustering optimizes for human navigational logic, whereas PTA optimizes for equity accumulation at commercial endpoints. Traditional systems tend to degrade above roughly 500 URLs as equity disperses across unmanaged URL populations. By contrast, PTA is designed to remain coherent at much larger scale, because canonical governance, intent stratification, and crawl-share modeling are applied at template level rather than managed editorially per publication.
How is entity drift detected and corrected within a content cluster?
Entity drift is identified through periodic entity co-occurrence audits comparing the cluster’s current entity classification profile against its baseline and against top-ranking competitor content. The team extracts named entities from every cluster URL using a consistent NLP extraction method. Subsequently, primary entity presence rate is calculated against an operational target of roughly 90% of cluster URLs, and secondary entity co-occurrence rates are checked. Drift manifests when primary entity presence falls below 80% or when content updates introduce competing entity associations that rival the primary entity in topical classification. Correction requires targeted content updates to affected URLs — focused on natural, coherent topical framing, not keyword stuffing — and schema markup realignment. New URL publication during entity drift remediation is counterproductive because it expands entity surface area without resolving existing dilution.
What is the correct application of the cannibalization decision tree when SERP overlap exceeds 25%?
When SERP overlap between two domain URLs exceeds 25%, structural correction is warranted. The first step is intent position comparison in the stratification matrix. If both URLs occupy the same intent stratum, consolidation through 301 redirect is the standard approach — the lower-performing URL merges into the stronger. If URLs occupy adjacent but distinct intent strata, however, structural re-segmentation is the appropriate correction: rewrite one URL to anchor firmly in its assigned intent position through topical focus adjustment and content format changes. Canonical tag assignment is appropriate only when one URL functions as the definitive ranking target and the other provides contextual support with no independent ranking objective. Canonical does not resolve genuine intent competition — instead, it suppresses the symptom while the structural conflict persists.
How does production sequencing affect authority accumulation speed?
Sequencing compresses authority accumulation timelines by ensuring pillar pages enter an equity-reinforced environment from the moment of publication. A pillar page published as the first URL in an empty cluster must build authority entirely through external link acquisition — a slow, externally dependent process. By contrast, a pillar page published after commercial target pages are already indexed, with wave-two cluster articles prepared for immediate internal linking, receives equity from multiple inbound sources from day one. In practice, sequenced publication tends to produce measurable crawl frequency advantages within 14 to 21 days of pillar publication — verifiable in server logs — compared to the longer timelines typical of randomly sequenced cluster builds that require retroactive internal link correction.
What measurement signals confirm that Programmatic Topical Authority is functioning correctly at the commercial layer?
Commercial layer validation looks for three confirming signals across distinct measurement windows. In the 30-day window, crawl frequency increases for commercial target URLs in server logs — a shift toward more frequent crawl cycles — confirm that equity flow engineering delivers crawl priority to the correct destinations. In the 45-to-60-day window, GSC impression share growth for commercial target keyphrases without corresponding position changes confirms that SERP feature acquisition — schema enhancements, rich results — is functioning. In the 90-day window, organic conversion attribution from cluster-origin traffic to commercial target conversions confirms that the full authority pipeline is operational. Absence of any signal in its expected window indicates a specific layer failure requiring targeted diagnosis, not broad architectural revision.
What distinguishes index governance from crawl budget optimization?
Crawl budget optimization is a technical intervention that addresses symptoms: crawl frequency imbalances, response code patterns, rendering delays. Index governance, by contrast, is an architectural decision layer that determines which URLs exist in the index and in what canonical relationship to each other. Index governance operates before crawl budget optimization becomes necessary. When every URL pattern in the site architecture has an assigned canonical treatment that the CMS template layer enforces automatically, crawl budget waste is structurally prevented rather than requiring periodic remediation. On sites where crawl budget optimization is a recurring task, the root cause is typically absent or inconsistently applied index governance. Resolving the governance layer removes the need for ongoing crawl budget intervention.
Related SEO Articles
- Internal Linking Graph Architecture for Large-Scale SEO Systems — Methodology for modeling, auditing, and engineering internal link equity flow across URL populations exceeding 1,000 nodes, including node weight calculation, concentration zone design, and leak point identification.
- Intent Stratification Matrix: Construction and Governance — Technical reference for building and maintaining an intent stratification model, including stratum definition, URL assignment methodology, pre-publication overlap simulation, and SERP overlap monitoring protocol.
- Technical SEO Audit Framework: Crawl Governance and Canonical Compliance — Audit framework covering crawl log segmentation methodology, canonical directive assignment by URL pattern type, and template-level enforcement implementation across CMS platforms.
- Entity Co-Occurrence Modeling and Knowledge Graph Alignment — Reference documentation for entity density scoring, primary and secondary entity target definition, schema reinforcement methodology, cross-cluster contamination detection, and entity drift remediation protocol.