
Technical SEO rendering architecture governs the three-stage pipeline between Googlebot fetching a URL, processing its JavaScript, and committing the page to the index. Failures at any stage — deferred rendering, hydration-injected directives, or client-side canonical tags — produce index instability that is invisible in GSC for weeks. This guide defines the detection methodology, rendering architecture selection model, and deployment validation system required to control indexation outcomes at enterprise scale.
The structural decisions that upstream rendering architecture depend on — URL generation, crawl path control, and template-level directive governance — are covered in the technical SEO architecture framework. This guide extends that foundation into the rendering layer specifically.
What Rendering Architecture Actually Controls in SEO
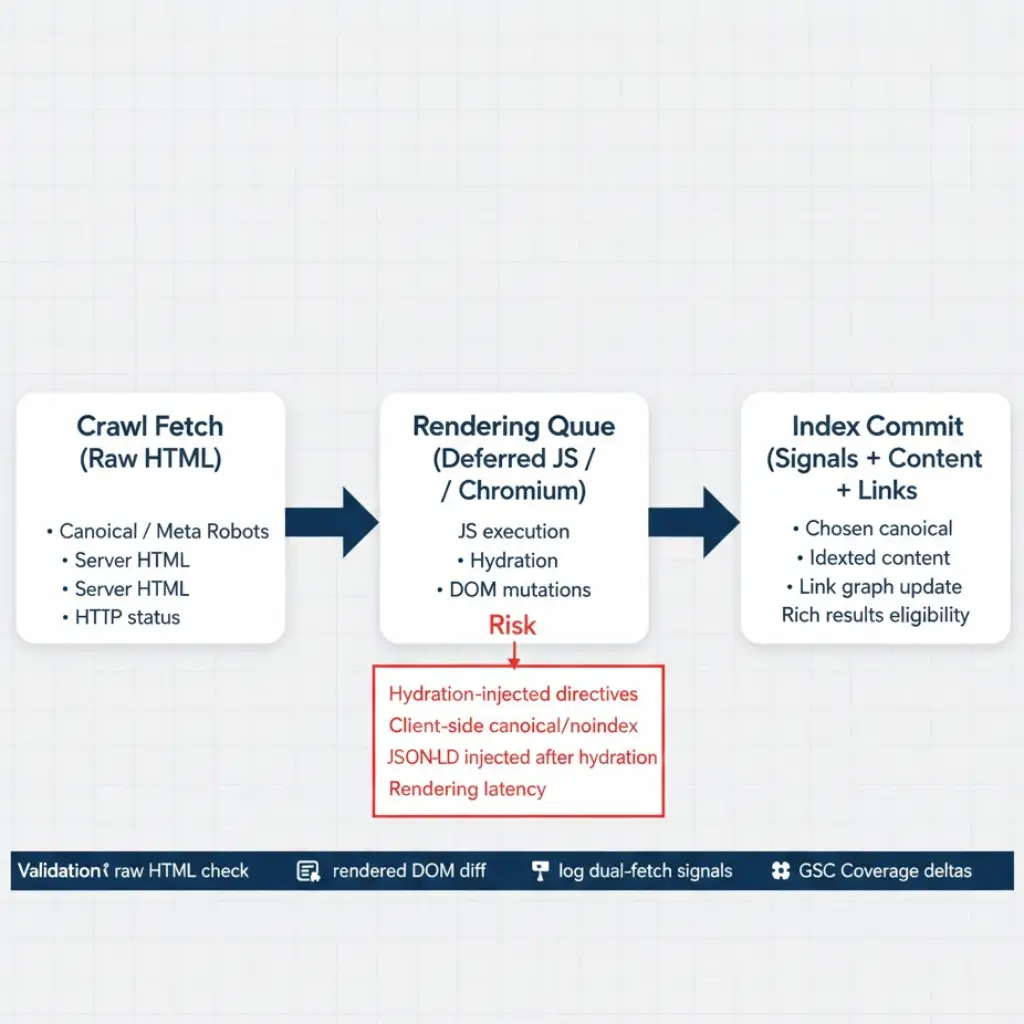
Rendering architecture determines when and whether page content, SEO directives, and structured data are visible to Googlebot. The crawl event and the render event are two separate pipeline stages. Googlebot fetches raw HTML first. JavaScript rendering — if required — is queued separately and processed later, sometimes days or weeks after the initial crawl.
Google’s Search documentation explicitly distinguishes between crawling and rendering as independent operations. This separation has direct SEO implications: a canonical tag injected post-hydration is invisible to Googlebot at crawl time. A noindex directive applied via JavaScript may not be processed until the rendering queue completes. Content inside a React component that renders client-side does not exist in Google’s index until the render event fires — and that event is not guaranteed within any defined timeframe.
At enterprise scale, rendering architecture decisions affect millions of URLs simultaneously. A single framework change — migrating from SSR to CSR, enabling lazy hydration, or switching to a new JavaScript bundler — can silently degrade indexation across entire template families without producing immediate ranking signals. The degradation accumulates over weeks before it surfaces in GSC Coverage reports.
The JavaScript Rendering Pipeline — How Googlebot Actually Processes Pages
Understanding the exact rendering pipeline sequence is prerequisite to diagnosing rendering failures. Googlebot does not render JavaScript inline during the crawl fetch. The pipeline operates in three discrete stages.
Stage one is the crawl fetch. Googlebot sends an HTTP request and receives the raw server response — the HTML payload exactly as delivered by the web server or CDN, before any JavaScript executes. This raw HTML is what Googlebot uses for immediate indexation decisions: canonical tags, meta robots directives, and any content present in server-side markup.
Stage two is rendering queue assignment. If the page contains JavaScript that affects content or directives, Googlebot places the URL in a deferred rendering queue. The delay before rendering begins depends on Google’s capacity and the site’s crawl priority. For high-authority, frequently crawled pages, rendering may occur within hours. For lower-priority pages on sites with crawl budget constraints, rendering delay can extend to weeks. The technical SEO crawl budget optimization framework directly affects rendering queue priority — pages that receive frequent crawl allocation also receive faster rendering attention.
Stage three is render-time processing. Googlebot executes JavaScript in a headless Chromium environment, processes the rendered DOM, and updates its understanding of the page’s content, links, and directives. Only at this stage do client-side rendered components, lazy-loaded content, and JavaScript-injected structured data become visible. However, any directive conflicts between the raw HTML (stage one) and the rendered DOM (stage three) create indexation ambiguity that Google resolves independently.
Technical SEO Rendering Architecture — CSR vs SSR vs SSG vs ISR
Architecture selection is the upstream decision that determines every downstream rendering SEO risk. Each rendering model carries a distinct indexation risk profile, crawl behavior, and operational maintenance cost.
| Architecture | HTML at Crawl Time | SEO Indexation Risk | Crawl Budget Impact | Recommended Use Case |
|---|---|---|---|---|
| Server-Side Rendering (SSR) | Full HTML in raw response | Low — all directives readable at crawl fetch | Neutral — server load scales with crawl frequency | Dynamic content requiring fresh data per request; product pages, category pages |
| Static Site Generation (SSG) | Full pre-rendered HTML | Very Low — fastest crawl-to-index pipeline | Low — CDN-served responses reduce server load and support higher crawl rates | Content-heavy sites with predictable URL patterns; blogs, documentation, landing pages |
| Client-Side Rendering (CSR) | Minimal shell HTML only | High — content and directives invisible until render queue completes | High waste — crawl budget consumed without indexable content at fetch time | Authenticated dashboards, internal tools; never for public indexable content |
| Incremental Static Regeneration (ISR) | Stale pre-rendered HTML until revalidation | Medium — content freshness lag; directives readable but may reflect outdated state | Low — CDN-served until revalidation threshold | High-volume content with tolerable freshness windows; large e-commerce catalogs |
| Hybrid (SSR + CSR hydration) | SSR shell with hydrated components | Medium — initial HTML indexed; hydration-only components invisible until render | Neutral — depends on proportion of hydrated vs server-side content | Interactive applications requiring SEO on primary content; SaaS product pages |
| Dynamic Rendering | Full HTML for Googlebot only | Low for Googlebot; risk of cloaking classification | Neutral | Temporary mitigation only; migrate to SSR as permanent solution |
The selection principle is straightforward: any URL intended for indexation must deliver complete, directive-accurate HTML in the raw server response. Architectures that defer content or directives to the rendering queue introduce indexation risk proportional to rendering queue latency and crawl budget allocation. SSR and SSG are the only architectures that eliminate rendering risk entirely for public-facing indexable content.
Hydration Risk and Directive Reliability
Hydration is the process by which a server-rendered HTML shell is enhanced with JavaScript to become an interactive application. From a user perspective, hydration is transparent. From a rendering SEO perspective, hydration is the primary source of directive unreliability in modern JavaScript frameworks.
The failure mode: a page is server-rendered with full HTML content, but canonical tags, meta robots directives, or structured data are managed by a client-side state management library — React Helmet, Next.js Head, Vue Meta. These libraries inject directives into the DOM after hydration completes. At crawl time, the raw HTML response contains either no directive or a placeholder directive. Google reads the crawl-time HTML and acts on whatever is present — or absent — at that moment.
Canonical or noindex directives injected exclusively via client-side JavaScript are operationally unreliable. Googlebot separates the crawl fetch from the render event, meaning the rendering queue must complete before JavaScript-injected directives are visible. If the rendering queue is delayed — due to crawl budget constraints or server response latency — Google may index a page based solely on its raw HTML state, which carries no canonical declaration and no robots directive. Validate server-side HTML delivery via curl before any JavaScript executes; any directive absent from the raw response is at risk. This is not an edge case on high-traffic deployments — it is a documented failure pattern affecting sites that rely on client-side head management at scale.
The detection method is a two-step comparison. First, fetch the URL via curl and inspect the raw response headers and HTML for canonical tags, meta robots, and structured data. Second, render the same URL in Chrome DevTools and inspect the DOM for the same elements. Any element present in the DOM but absent from the raw curl response is hydration-injected and unreliable for crawl-time indexation control. The fix is server-side directive delivery — all canonical tags, meta robots, hreflang, and Schema.org structured data must be present in the server-rendered HTML before any JavaScript executes.
Rendering Failure Classification — Impact and Detection
Rendering failures are not binary. They occur across a spectrum of severity, each with distinct SEO impact, detection signal, and remediation path. Classifying the failure type before applying a fix prevents misdiagnosis and misdirected engineering effort.
| Failure Type | SEO Impact | Detection Method | Fix |
|---|---|---|---|
| Client-side canonical injection | Google selects incorrect canonical; index instability across template family | curl raw HTML vs rendered DOM comparison; canonical absent in raw response | Move canonical to server-rendered HTML; validate via curl post-deploy |
| Client-side noindex injection | Pages indexed that should be excluded; or pages excluded based on stale render state | curl raw HTML shows no meta robots; rendered DOM shows noindex | Deliver meta robots server-side; remove dependency on JavaScript head management for critical directives |
| JavaScript-only content | Primary page content not indexed; keyword signals absent; internal links in JS components not followed at crawl time | curl output vs rendered DOM content diff; missing text in raw HTML | Move primary content to server-rendered HTML; reserve CSR for interactive enhancement only |
| Lazy-loaded structured data | Rich results suppressed; entity signals absent from crawl-time HTML | curl shows no schema; GSC Rich Results Test fails on raw URL | Inline structured data in server-rendered HTML; validate with Schema.org Rich Results Test against raw response |
| Hydration mismatch | Content flickering; inconsistent rendered state; potential canonical drift between crawl and render states | Server HTML vs hydrated DOM content mismatch in diff tool; GSC Coverage “Crawled — currently not indexed” spike | Audit hydration lifecycle; ensure server and client render identical initial state |
| Rendering timeout | Page not indexed; URLs accumulate in “Discovered — currently not indexed” state | GSC “Discovered — currently not indexed” spike; render queue latency confirmed via log timestamps | Reduce JavaScript bundle size; optimize server response time; implement SSG for stable content types |
| ISR stale state delivery | Outdated content indexed; canonical pointing to deprecated URL structure post-migration | Fetch page via curl; compare response headers for CDN cache age; verify canonical against current URL spec | Force ISR revalidation post-migration; verify CDN cache purge completes before crawl re-engagement |
Each failure type requires a distinct diagnosis path. Running the curl comparison protocol across all major template types after any deployment is the minimum viable detection system. Deploying without this check allows rendering failures to accumulate silently until GSC Coverage anomalies surface — typically four to eight weeks after the causal deployment.
Rendering Queue Behavior and Crawl Budget Interaction
The rendering queue is a finite resource. Google allocates rendering capacity across all sites it crawls, prioritizing pages based on crawl authority, freshness signals, and server response performance. Consequently, sites with inefficient crawl budget allocation — large volumes of non-canonical URLs consuming Googlebot requests — also experience degraded rendering queue priority for their canonical content pages.
The interaction is measurable. In server log data, compare the timestamp of Googlebot’s crawl fetch for a given URL against the timestamp of the subsequent render-time fetch (identifiable by the Googlebot/2.1 (compatible; Googlebot/2.1; +http://www.google.com/bot.html) string in the rendering agent context). The delta between these timestamps is the rendering latency for that URL. On sites with well-optimized crawl budgets and fast server response times, rendering latency for high-priority pages commonly falls under 24 hours. On sites with high crawl waste, rendering latency on canonical content pages can extend to two weeks or longer.
Improving rendering queue throughput therefore requires both the rendering architecture changes described in this guide and the crawl waste reductions defined in the technical SEO crawl budget optimization framework. These are not independent workstreams — they share the same upstream resource constraint.
Core Web Vitals as a Rendering Architecture Output
Core Web Vitals scores are not independent of rendering architecture — they are a direct output of it. Largest Contentful Paint (LCP), Cumulative Layout Shift (CLS), and Interaction to Next Paint (INP) each reflect specific rendering pipeline behaviors that are determined by architecture selection before any performance optimization is applied.
CSR architectures produce structurally poor LCP scores because the largest contentful element — typically a hero image or primary heading — cannot render until the JavaScript bundle executes and the component tree hydrates. SSG and SSR architectures deliver the LCP element in the initial HTML payload, enabling browser paint before any JavaScript executes. The Core Web Vitals thresholds — LCP under 2.5 seconds, INP under 200 milliseconds, CLS under 0.1 — are achievable within an SSR or SSG architecture without heroic optimization effort. Achieving the same thresholds under CSR requires aggressive code splitting, preloading strategies, and caching layers that add engineering complexity without addressing the architectural root cause.
CLS failures specifically correlate with hydration timing. When server-rendered HTML is replaced by hydrated content that has different dimensions or layout, the layout shift metric registers the delta. Sites with large hydration-injected content blocks — navigation elements, hero sections, modal frameworks — routinely fail CLS thresholds for this reason. The fix is either SSR with stable initial layout or explicit dimension reservation in server-rendered HTML so hydration does not produce layout movement.
Structured Data Rendering Validation Protocol
Structured data reliability depends entirely on rendering architecture. Schema injected via JavaScript is subject to the same rendering queue latency as any other client-side content — it may not be visible to Googlebot at crawl time, and its absence degrades rich result eligibility and entity signal clarity.
Problem: Structured data is implemented via a JavaScript framework’s head management library, invisible in raw HTML, and absent from crawl-time indexation decisions.
Cause: Development teams implement Schema.org structured data using component-level head injection — React Helmet, Next.js Script, Nuxt useHead. These approaches insert structured data into the DOM post-hydration. The server-rendered HTML contains no JSON-LD block; the structured data exists only in the rendered DOM state.
Detection: Run the Google Rich Results Test against the target URL using the “Test Live URL” option, which renders the page. Then fetch the same URL via curl and search the raw response for the JSON-LD block. If the Rich Results Test passes but the curl response contains no structured data, the schema is client-side injected and unreliable. Additionally, compare GSC’s “Enhancements” report against expected schema coverage — systematic gaps in rich result eligibility by template type indicate rendering-dependent schema delivery.
Fix: Inline all structured data in the server-rendered HTML response. For SSR frameworks, this means rendering the JSON-LD block server-side and including it in the initial HTML payload. For SSG, structured data should be generated at build time and embedded in the static HTML output. Post-deployment, verify by curling a representative URL from each template type and confirming the JSON-LD block is present in the raw response before any JavaScript executes.
Log-Level Rendering Detection Signals
Server logs contain rendering signals that GSC reports do not surface. Extracting these signals requires knowing what to look for in Googlebot’s crawl pattern data.
The primary signal is dual-fetch behavior. When Googlebot crawls a page that contains JavaScript, it generates two distinct log entries: the initial crawl fetch (user agent Googlebot/2.1) and a subsequent render fetch (identifiable by the rendering-specific user agent string or by the request pattern — same URL, different accept headers, arriving seconds to hours later). Pages that generate only a single log entry are being processed without rendering — either because they are serving full server-side HTML and Google is not queuing them for JavaScript processing, or because the rendering queue is not reaching them.
The secondary signal is response time correlation. Pages with server response times consistently above 500ms receive lower crawl frequency and correspondingly lower rendering queue priority. Extract average response times per URL pattern from log data and cross-reference against rendering queue latency estimates. Slow-responding templates are rendering bottlenecks independent of their JavaScript complexity.
The tertiary signal is the ratio of crawl fetches to render fetches across URL types. In a healthy rendering architecture, canonical content pages should show a high ratio of render fetches relative to crawl fetches — indicating that Googlebot is completing the rendering pipeline for those URLs. Non-canonical URL types — parameter variants, facet combinations — should show low or zero render fetch activity, indicating that Google is not investing rendering resources in waste URL patterns. Running this analysis monthly and comparing against the baseline crawl share model from the technical SEO crawl budget optimization log segmentation provides a complete rendering efficiency picture.
Index Drift from Rendering Changes
Index drift caused by rendering changes is among the most difficult root causes to diagnose because the causal event — a framework update, a hydration library change, a CDN configuration shift — does not produce an immediate indexation signal. The impact accumulates over the four to eight weeks it takes for Googlebot to recrawl affected pages, compare the new rendering output against its cached understanding, and update Coverage states accordingly.
The typical drift pattern following an undetected rendering regression: canonical content pages begin appearing in “Crawled — currently not indexed” at increasing rates. “Duplicate without user-selected canonical” counts rise as canonical tags disappear from raw HTML responses. Rich result counts in the GSC Enhancements report decline as structured data becomes render-dependent. None of these signals are immediately attributable to a rendering change without log and crawl comparison data from the deployment window.
Prevention requires integrating rendering validation into the deployment pipeline before release. The minimum viable rendering check at deployment consists of: curl verification that canonical, meta robots, and structured data are present in the raw HTML response for one URL from each modified template type; a diff comparison between the pre-deployment and post-deployment raw HTML for the same sample set; and a GSC fetch-and-render comparison for critical template representatives. Patterns of common rendering regressions introduced at deployment are documented in the technical SEO implementation mistakes reference — reviewing that taxonomy before any framework migration substantially reduces regression risk.
Deployment Guardrails for Rendering Stability
Rendering stability requires the same governance model applied to canonical and robots directive control — pre-deployment validation, automated checks, and post-deployment monitoring on a defined schedule.
The rendering-specific deployment guardrails that must run before any framework change, JavaScript library update, or CDN configuration change reaches production:
Raw HTML directive verification: Curl each modified template type and confirm canonical tags, meta robots, and structured data are present in the raw response. Any directive absent from the raw response is a deployment blocker.
Hydration state consistency check: Compare the server-rendered HTML for key templates against the hydrated DOM state in Chrome DevTools. Any content, link, or directive present in the DOM but absent from the raw HTML is hydration-dependent and must be moved server-side.
Core Web Vitals regression check: Run Lighthouse against a representative URL sample pre- and post-deployment. LCP regressions above 10% are a hold condition for frameworks that affect rendering pipeline timing. Evaluate against the Core Web Vitals thresholds — LCP, INP, and CLS — as a rendering quality gate.
Structured data continuity: Curl all template types and verify JSON-LD blocks are present in the raw response. Compare structured data field completeness against the pre-deployment baseline. Any required field absent from the raw response requires resolution before deployment proceeds.
Rendering latency baseline comparison: After deployment, pull log data for the first 48–72 hours and compare render-fetch counts per template type against the pre-deployment baseline. A significant drop in render-fetch frequency for canonical content pages indicates a rendering architecture regression requiring rollback evaluation.
These guardrails integrate with the broader deployment governance system defined in the technical SEO checklist. Rendering validation is a blocking condition in the release pipeline — not a post-deployment audit step. Running the technical SEO audit rendering module on a quarterly cadence provides the ongoing monitoring layer between deployment events.
Architecture Validation and Monitoring Protocol
Validation operates across three timeframes following any rendering architecture change or deployment affecting JavaScript execution.
Immediate validation (0–48 hours): Run the full curl verification protocol across all modified templates. Confirm canonical, meta robots, and structured data present in raw HTML. Pull log data and verify Googlebot is crawling the modified templates with expected frequency. Any anomaly — missing directives, unexpected 500 responses, Googlebot crawl gaps — requires rollback evaluation before the rendering queue begins processing the new template state.
Short-term validation (week 2–4): Monitor GSC Coverage states for the modified template types. Unexpected increases in “Crawled — currently not indexed” or “Duplicate without user-selected canonical” indicate a rendering regression affecting canonical delivery. Compare GSC Coverage counts against the pre-deployment baseline — any statistically significant shift in exclusion rates requires log-level investigation to identify the causal rendering failure type.
Medium-term validation (week 4–8): Index composition for the modified templates should stabilize. Compare the indexed URL count per template type against pre-deployment baseline. Revenue-critical templates should show stable or improving indexation rates. Structured data coverage in GSC Enhancements should match the expected schema deployment scope. Any divergence between expected and actual indexed counts at this timeframe indicates a rendering failure that passed initial validation but manifested under rendering queue processing conditions.
Frequently Asked Questions
Why does Google sometimes index client-side rendered content correctly if CSR is unreliable?
Google does render JavaScript — but on a deferred schedule that depends on crawl priority and rendering queue capacity. For high-authority pages crawled frequently, the rendering queue may process pages within hours, producing functional indexation of client-side content. However, reliability is not the same as occasional success. At scale, rendering queue latency is unpredictable, and CSR architectures produce systematically slower indexation, higher rates of “Discovered — currently not indexed” accumulation, and increased vulnerability to rendering regressions following framework updates. SSR and SSG eliminate this variability entirely for public-facing indexable content.
How do you detect whether a directive is server-side or client-side injected?
Fetch the URL with curl using a standard Googlebot user agent string and inspect the raw response body. If the canonical tag, meta robots directive, or JSON-LD block is absent from the curl response but present in Chrome DevTools’ rendered DOM, the directive is client-side injected. This two-step comparison — curl versus rendered DOM — is the definitive detection method. Tools like Screaming Frog can extract canonical tags from both raw HTML and rendered output simultaneously, enabling batch detection across large URL sets.
Does Next.js SSR guarantee server-side directive delivery?
Not automatically. Next.js SSR delivers the initial HTML server-side, but head management libraries like next/head and third-party equivalents can still inject directives via client-side hydration if implemented incorrectly. Specifically, canonical tags and meta robots directives defined inside component-level head blocks that are conditionally rendered based on client state — authentication state, A/B test assignments, feature flags — may not be present in the server-rendered payload. The only definitive verification is curl comparison: fetch the URL server-side and confirm each directive appears in the raw HTML response before any JavaScript executes.
What is the SEO risk of Incremental Static Regeneration during site migrations?
ISR introduces a staleness window between content updates and CDN cache revalidation that creates measurable indexation risk during migrations. If a migration changes URL structures, canonical declarations, or redirect patterns, ISR-cached pages may continue serving the pre-migration canonical configuration to Googlebot for the duration of the revalidation window. Googlebot crawling stale ISR content during a migration will process outdated canonicals and may consolidate signals to deprecated URL patterns. Mitigate this by forcing full ISR revalidation before re-engaging crawl demand post-migration, and by verifying CDN cache purge completion via log data before removing legacy redirect rules.
How does rendering architecture affect internal link discovery?
Internal links rendered exclusively via JavaScript — navigation components, related content widgets, dynamically generated anchor tags — are not discovered at crawl time. They are only available to Googlebot after the rendering queue processes the page, introducing the same latency and reliability risk as client-side content. For link topology purposes, any internal link that does not appear in the raw HTML response at crawl time cannot contribute to crawl path efficiency or PageRank distribution at crawl frequency. Move navigation, hub links, and high-priority contextual links to server-rendered HTML to ensure they are available for crawl-time link graph construction.
What is the relationship between rendering architecture and Core Web Vitals scoring?
Core Web Vitals scores are a direct output of rendering architecture selection, not an independent optimization problem. LCP is structurally determined by when the largest contentful element is available for paint — SSR and SSG deliver this element in the initial HTML, enabling early paint. CSR requires the JavaScript bundle to execute and the component tree to hydrate before any paint is possible. CLS is directly caused by hydration-induced layout shifts when server-rendered HTML dimensions differ from hydrated component dimensions. INP reflects JavaScript execution blocking and hydration overhead. Resolving Core Web Vitals failures under CSR requires compensating for an architectural choice that structurally degrades these metrics — migrating to SSR or SSG addresses the root cause rather than the symptom.