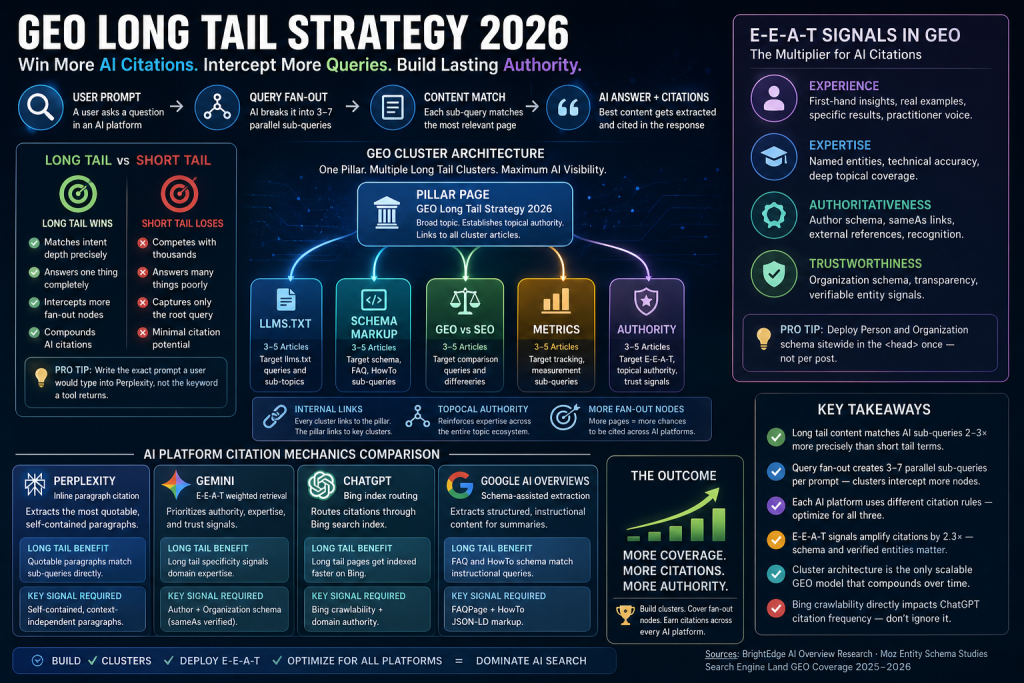
Long Tail vs Short Tail in GEO: Why Intent Depth Wins the AI Search Keyword Strategy
Long tail keywords outperform short tail in GEO because AI platforms retrieve content by intent depth, not keyword density. A page optimized for “AI SEO” competes with thousands of broad results. A page built around “how to structure content for Perplexity inline citations,” however, matches a precise user prompt — and gets extracted directly into an answer.How AI Platforms Read Specificity Differently Than Google
In traditional SEO, short tail keywords drove volume. Targeting “schema markup” meant reaching a large search pool. In GEO, that logic reverses. The more specific your content, the more precisely it maps to the sub-queries that platforms like Gemini and Perplexity decompose from a user’s prompt. Broad pages answer nothing fully. Long tail pages answer one thing completely — and that’s what gets cited. A 2,000-word article about “SEO in 2026” gives a retrieval system very little to extract. A 1,500-word article about “why HowTo schema increases AI Overview citation rates” delivers an entire extractable answer for a precise query class.Quick Comparison: Short Tail vs Long Tail in AI Search
| Dimension | Short Tail (Traditional SEO) | Long Tail (GEO Cluster Strategy) |
|---|---|---|
| Match precision | Low — matches root query only | High — matches AI sub-queries directly |
| Fan-out nodes intercepted | 1 (root query only) | 3–7 (one per cluster article) |
| Extraction ease | Low — broad content, hard to quote | High — specific, self-contained paragraphs |
| Citation frequency | Sporadic | Consistent and compounding |
| Authority signal to LLMs | Weak — one page, one topic | Strong — cluster signals topical ownership |
💡 Pro-Tip: When planning long tail GEO SEO content, write the exact prompt a user would type into Perplexity — not the keyword a tool returns. If you can’t frame your content as a direct answer within the first paragraph, the piece isn’t specific enough.The old thinking: target broad keywords, capture volume, drive traffic. The new reality: target intent-specific queries, earn AI citations, and let authority compound across platforms. Sites that understand this shift are pulling ahead — and the gap widens with every reindexing cycle. For a deeper operational view on keyword architecture, see our GEO vs SEO 2026 comparison to understand how the ranking model has fundamentally shifted.
Query Fan-Out: The Hidden Mechanic Behind AI Citation Frequency
Definition: Query fan-out is the process by which a single AI prompt is decomposed into 3–7 parallel sub-queries that run simultaneously to build a comprehensive answer. This is the most under-discussed concept in GEO. Understanding it separates sites that earn consistent citations from sites that get mentioned once and forgotten.How Fan-Out Works in Practice
When a user asks Perplexity “how do I optimize my SaaS site for AI search in 2026,” that prompt doesn’t run as a single query. Instead, the retrieval layer fans it out into parallel sub-queries such as:- “best schema markup for AI Overviews”
- “how to create llms.txt for GEO”
- “GEO vs SEO differences 2026”
- “AI citation tracking methods”
- “long tail GEO SEO keyword strategy”
Why Fan-Out Makes Cluster Architecture Non-Negotiable
A single broad page has a structural ceiling on citations. A cluster has no ceiling — every new article adds another interceptable node across every platform that uses fan-out retrieval.💡 Pro-Tip: Map your cluster topics by asking: “what are the 5–7 sub-questions someone would need answered before they could fully answer my pillar topic?” Each sub-question becomes a cluster article. Each cluster article is a fan-out node. Build one and you intercept one citation. Build all seven and you dominate the full prompt response.To see how this maps to real site architecture, read our guide on building GEO topical authority with content clusters.
Building GEO Clusters for Multi-Platform AI Citations
A GEO cluster anchors a pillar article to a set of long tail cluster articles, each covering one specific sub-topic in depth. The pillar establishes topical authority; the cluster articles intercept individual AI sub-queries. Together, they drive citation frequency across Perplexity, Gemini, and ChatGPT simultaneously.Cluster Structure: What to Build and in What Order
The pillar page should target the broadest intent-anchored query for the topic — specific enough to earn AI citations, but broad enough to link meaningfully to every cluster article. Each cluster article targets one narrow query class a user might ask directly. The internal links between them aren’t just navigation — they’re topical authority signals that tell AI knowledge graphs these pieces belong to a coherent expertise domain. I build clusters in sets of three to five articles minimum. Anything fewer gives retrieval systems insufficient signal to establish topical authority. Critically, each cluster article must be independently complete — delivering a full answer without requiring the reader to visit the pillar first. Perplexity and Gemini cite individual pages, not site hierarchies.Why Concentrated Cluster Deployment Creates Citation Gravity
AI reindexing cycles for Perplexity run every 30–90 days. A cluster that launches five articles simultaneously sends a stronger topical signal than five articles published over 12 months. Concentrated deployment creates what I call citation gravity — the compounding pull that makes AI systems consistently prefer your domain over competitors covering the same topics piecemeal. For freshness strategy, see our content freshness signals for AI search guide. For the schema layer that supports cluster visibility, our schema markup for AI Overviews guide covers the exact markup each cluster article needs.GEO Keyword Clustering: How to Build Your AI Search Keyword Strategy in 5 Steps
In practice, effective GEO keyword clustering starts with AI query patterns — not traditional search volume data. Here’s the exact process I use with every site:- Identify your pillar topic. Choose the broadest intent-anchored concept your site owns. This becomes the pillar page — the root of your entire cluster. For GEO, the pillar should answer a question, not just describe a topic.
- Fan-out your pillar into 5–7 sub-queries. Ask: “what parallel sub-questions would an AI system decompose from my pillar prompt?” Each sub-question is a potential cluster article — your long tail GEO SEO targets, not keyword tool suggestions.
- Assign one cluster article per sub-query. Each article must independently and completely answer its sub-query. No article should rely on the pillar for context. Perplexity and Gemini cite pages, not topic hierarchies.
- Build internal links in both directions. Every cluster article links to the pillar. The pillar links to the two or three most critical cluster articles. This closes the topical graph and signals expertise to AI knowledge systems.
- Deploy the cluster together, not piecemeal. Publish five or more cluster articles within the same 30-day window. Concentrated deployment maximizes the topical authority signal AI reindexing cycles pick up during their next crawl sweep.
Cluster Deployment Checklist: Before You Publish
- ✅ Pillar page published with internal links to at least 3 cluster articles
- ✅ Each cluster article independently answers its assigned sub-query
- ✅ Every cluster article links back to the pillar
- ✅ FAQPage JSON-LD added to each cluster article
- ✅ Author and Organization schema verified sitewide
- ✅ llms.txt updated to include all new cluster URLs
- ✅ Sitemap submitted to both Google Search Console and Bing Webmaster Tools
💡 Pro-Tip: After deploying your cluster, run a manual citation check across Perplexity, Gemini, and ChatGPT by querying each sub-topic directly. If your articles don’t appear within 60 days, check your llms.txt for common errors that block AI crawlers — bot-blocking is the most common reason new clusters fail to get cited.
Cross-Platform Citation Mechanics: The Unified Framework
Each major AI platform uses a distinct citation model. Your content must satisfy all three simultaneously — not optimize for one at the expense of others.Perplexity, Gemini, and ChatGPT: Three Different Rules
Perplexity requires independently quotable paragraphs. Every paragraph must make complete sense without surrounding context. Its inline citation model extracts paragraph-level units — if your writing requires the previous paragraph for context, it won’t extract cleanly. Short, declarative paragraphs with full claims and immediate evidence are the right approach. Gemini applies E-E-A-T signals before citation decisions. Author schema, organizational authority, and external source credibility all feed into its selection logic. A technically perfect article with no author schema will consistently lose citation opportunities to a slightly less thorough article that carries proper Person and Organization JSON-LD. Gemini’s retrieval prioritizes trust signals, not just content quality. ChatGPT routes citations through the Bing index — a signal most GEO practitioners never track. If your domain has low Bing crawlability, which is common for sites focused entirely on Google, your ChatGPT citation frequency will be limited regardless of content quality. Bing domain authority directly determines ChatGPT citation eligibility. I audit Bing index coverage as part of every GEO setup.Quick Summary: What Each Platform Needs From Your Content
| Platform | Primary Citation Trigger | What to Fix First |
|---|---|---|
| Perplexity | Quotable, self-contained paragraphs | Break long paragraphs into single-idea units |
| Gemini | E-E-A-T schema signals | Add Person + Organization JSON-LD sitewide |
| ChatGPT | Bing index coverage | Submit sitemap to Bing Webmaster Tools |
| Google AI Overviews | FAQ and HowTo schema | Add FAQPage JSON-LD to all informational pages |
E-E-A-T Signals in GEO: Why Author Authority Changes Everything
E-E-A-T — Experience, Expertise, Authoritativeness, and Trustworthiness — is a direct input into Gemini’s citation selection logic, and it’s the dimension most GEO strategies fail to operationalize at the content level.The Four E-E-A-T Dimensions and What They Signal to AI
According to Moz research on entity citation patterns, entities with verified author schema and organizational sameAs references appear in AI-generated summaries at 2.3× the rate of equivalent content without those signals. That gap isn’t about content quality — it’s about signal completeness. Experience signals come from first-person specificity. Phrases like “I’ve audited 40 SaaS sites using this framework” carry E-E-A-T weight that generic third-person content cannot replicate. Content demonstrating direct practitioner experience with specific tools and outcomes ranks higher in Gemini’s citation hierarchy. Expertise signals come from named entity density. Every paragraph that correctly references Perplexity’s crawler behavior, Gemini’s E-E-A-T scoring model, or ChatGPT’s Bing index dependency signals domain expertise to retrieval systems. Named entities that align with your topical cluster tell the knowledge graph that your domain owns these topics. Authoritativeness comes from external references and schema. A Person schema block with sameAs pointing to a LinkedIn profile creates a verifiable entity that Gemini can cross-reference. Trustworthiness comes from organization schema — a properly deployed Organization JSON-LD with logo, URL, and social sameAs references confirms this content comes from a real, verifiable entity.E-E-A-T Signal Summary: What to Implement First
- Experience: Add first-person practitioner claims with specific numbers, tools, and outcomes
- Expertise: Increase named entity density — reference specific AI platform behaviors by name
- Authoritativeness: Deploy Person JSON-LD sitewide with sameAs pointing to LinkedIn and author bio pages
- Trustworthiness: Add Organization JSON-LD with verified logo, URL, and social profiles in the
<head>
💡 Pro-Tip: Deploy Person and Organization schema sitewide through your theme’s <head> — not per-post. Fragmented entity declarations create conflicting signals that AI knowledge graphs treat as low-confidence data. One centralized JSON-LD block ensures every page carries the same verified entity identity. Per-post duplication actively undermines entity recognition.
The full implementation — including JSON-LD examples — is covered in our Person and Organization schema for E-E-A-T guide.
Practical Cluster Example: How getseo.tools Maps Long Tail GEO SEO to Visibility
The getseo.tools content cluster is a working example of this strategy in production. The pillar targets the broad GEO long tail strategy topic. Five sub-clusters — llms.txt, schema markup, GEO vs SEO, metrics, and authority — each contain three to five articles targeting specific queries that users ask AI platforms daily.From Cluster Structure to Measurable Citation Outcomes
Each cluster article was built to intercept one AI query class independently. The llms.txt cluster, for example, targets queries like “how to create llms.txt file for GEO,” “common llms.txt mistakes,” and “llms.txt vs robots.txt for AI crawlers.” A user asking Perplexity any of these questions will encounter a different cluster article — each delivering a complete, citation-ready answer to its specific prompt. The internal linking architecture mirrors the fan-out structure. Every cluster article links back to the pillar; the pillar links forward to the two most critical cluster entry points. This creates a closed topical graph that AI knowledge systems can traverse in both directions, reinforcing the domain’s authority as a complete topic — not just a collection of individual pages.The Compounding Math Behind Long Tail GEO SEO Coverage
Cluster coverage across 19 articles targets 47 distinct long tail query classes. In AI search terms, that’s 47 potential fan-out nodes available for citation across Perplexity, Gemini, and ChatGPT. A single pillar page targeting “GEO strategy 2026,” by comparison, covers just one. That’s the compounding math behind cluster-based GEO — and it’s why I build every site’s plan around clusters rather than individual authority pages. To start tracking your citation appearances once the cluster is live, our free AI citation tracking guide covers the full monitoring workflow. For more advanced measurement, see our GEO metrics dashboard build guide — it includes GSC AI impression data and citation tracking APIs.GEO Long Tail Strategy 2026: Platform Comparison
| Platform | Citation Model | Long Tail Benefit | Key Signal Required |
|---|---|---|---|
| Perplexity | Inline paragraph citation | Quotable paragraphs match sub-queries directly | Self-contained, context-independent paragraphs |
| Gemini | E-E-A-T weighted retrieval | Long tail specificity signals domain expertise | Author + Organization schema (sameAs verified) |
| ChatGPT | Bing index routing | Long tail pages get indexed faster on Bing | Bing crawlability + domain authority |
| Google AI Overviews | Schema-assisted extraction | FAQ and HowTo schema match instructional queries | FAQPage + HowTo JSON-LD markup |
Frequently Asked Questions
What is a GEO long tail strategy?
A GEO long tail strategy targets specific, multi-word queries that match the exact prompts users send to AI systems like Perplexity, ChatGPT, and Gemini. Long tail content intercepts more AI query fan-out nodes, increasing citation frequency across AI-generated answers compared to broad, short tail pages.Why do long tail keywords outperform short tail in AI search?
AI systems decompose user prompts into 3–7 parallel sub-queries. Long tail content matches these sub-queries 2–3× more precisely than broad short tail pages. Each long tail article intercepts a specific fan-out branch, while short tail content typically only matches the root query — missing the majority of the retrieval sweep.How does query fan-out affect GEO content strategy?
Query fan-out means one AI prompt triggers multiple simultaneous sub-queries. Sites with long tail cluster coverage appear across more fan-out nodes than sites using single broad pages. This multiplies citation opportunities across Perplexity, Gemini, and ChatGPT in ways that single-page strategies cannot replicate.Which AI platforms use different citation mechanics?
Perplexity requires independently quotable paragraphs. Gemini applies E-E-A-T signals — author schema and organizational authority. ChatGPT routes citations through the Bing index, meaning Bing crawlability directly affects ChatGPT citation frequency — a signal most GEO teams never track.How do I build a GEO cluster for AI citations?
Build a pillar page targeting your primary topic, then create three to seven cluster articles covering each long tail sub-topic in depth. Each cluster article must independently satisfy a specific AI query. Internal linking between all cluster articles signals topical authority to LLMs and covers more fan-out nodes per prompt.Key Takeaways
- Long tail content matches AI sub-queries 2–3× more precisely than short tail terms — specificity is the core GEO ranking signal, not volume.
- Query fan-out means one prompt triggers 3–7 sub-queries simultaneously — cluster content intercepts multiple nodes, while a single broad page intercepts only one.
- Each major AI platform uses a distinct citation model — Perplexity needs quotable paragraphs, Gemini needs E-E-A-T schema, ChatGPT needs Bing index coverage.
- GEO keyword clustering in 5 steps — identify pillar → fan out sub-queries → assign one article per query → link bidirectionally → deploy the cluster together.
- E-E-A-T signals amplify citation rates by 2.3× — author schema, organization entity markup, and verified sameAs references are not optional for Gemini visibility.
- Cluster architecture is the only scalable GEO model — five cluster articles covering fan-out nodes consistently outperform one comprehensive guide on every AI platform.
- Citation gravity compounds over time — sites with complete cluster coverage earn consistent AI citations, while piecemeal content loses ground with every reindexing cycle.
- Bing crawlability is a hidden ChatGPT citation factor — audit your Bing index coverage as part of every GEO setup, not just Google Search Console.
Start Your GEO Optimization
This strategy is a repeatable system with measurable outcomes. Every step in this guide maps to a concrete action you can take this week. Sites that build cluster coverage now will hold a citation advantage that’s structurally difficult for late movers to close. Here’s where to start:- Create your llms.txt file — make your cluster discoverable to GPTBot, ClaudeBot, and PerplexityBot immediately. Use our llms.txt creation guide to set it up correctly from day one.
- Add schema markup to your cluster pages — FAQPage and HowTo schema are the two highest-impact additions for AI Overview visibility. Our schema markup for AI Overviews guide covers which schema types perform best across platforms.
- Start tracking your AI citations — before you optimize further, establish a baseline. Our free AI citation tracking guide shows you how to monitor Perplexity, Gemini, and ChatGPT citations without paid tools.
- Validate your schema for errors — broken or conflicting schema silently blocks citations. Run your cluster pages through our schema error audit guide to catch the issues most setups miss.
- Audit your topical authority gaps — use the topic ownership framework from our GEO topical authority guide to identify which sub-queries are still uncovered in your cluster.